The New Software Lifecycle
June 16, 2026
I co-wrote a Google whitepaper about how AI is changing the software lifecycle. I’m not going to summarize the whole thing. Instead, here are the handful of ideas in it I think actually matter, plus six figures you’re welcome to reuse.
Google published The New SDLC With Vibe Coding this week. I co-wrote it with Shubham Saboo and Sokratis Kartakis, and it’s the first in a short series.
It’s a Day 1 paper, so the early pages cover the basics: what an agent is, what “vibe coding” means, why the job is moving from writing code to judging it. If you read this blog you already have all of that. I’m going to skip it and write about the parts I think are worth your time, with six of the figures pulled out. Reuse the figures wherever you like.
An agent is a model plus a harness
Here’s the framing from the paper that I keep coming back to: an agent is a model plus a harness.
The model is one input. Everything else is the harness: the instructions and rule files, the tools and MCP servers, the sandboxes it runs in, the orchestration logic that spawns sub-agents and routes between models, the hooks that run deterministic code at set points, and the observability that tells you when it’s drifting. The paper’s rough split is 10% model, 90% harness. That sounds high until you’ve spent a week debugging one.
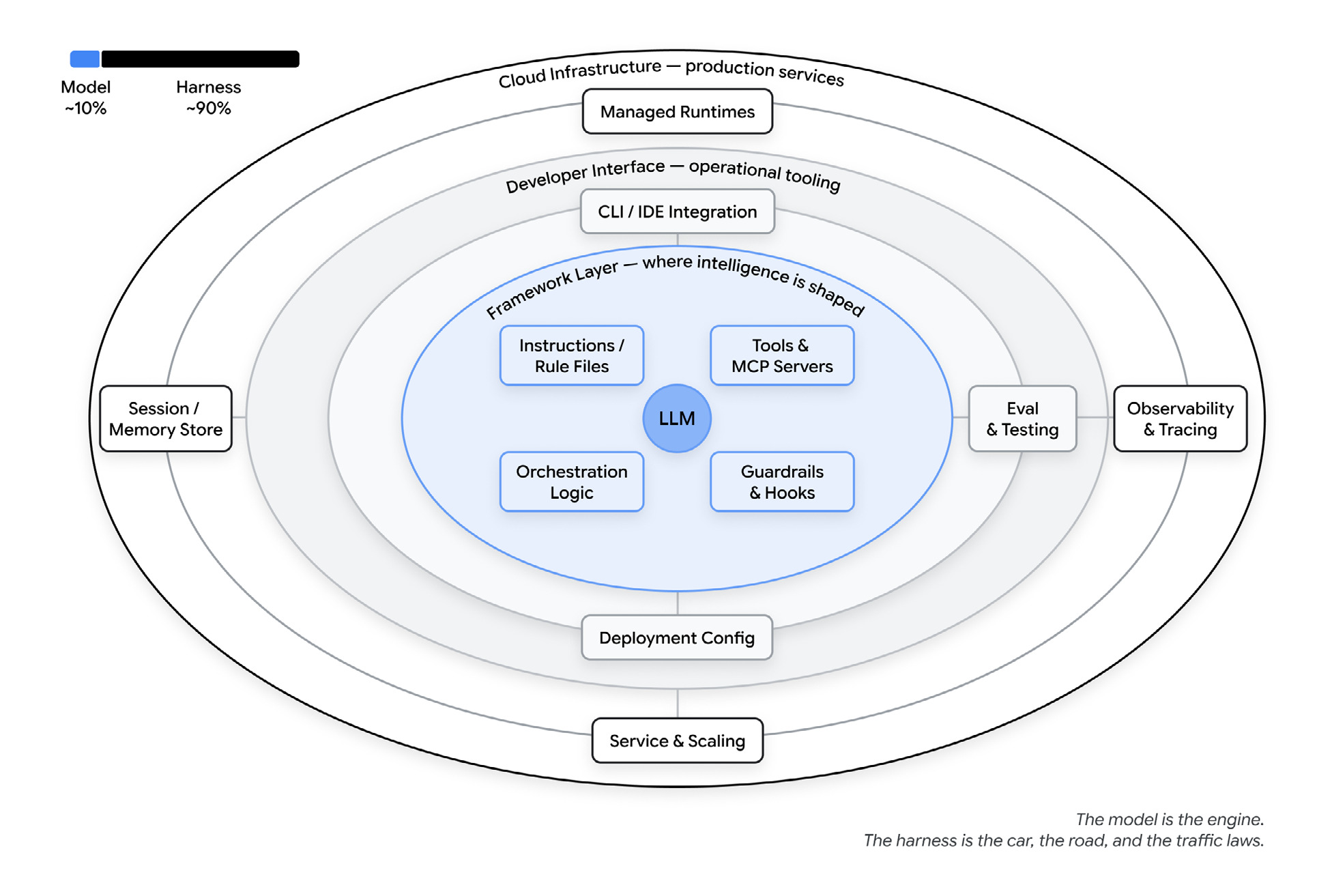 The model is the engine. The harness is the car, the road, and the traffic laws.
The model is the engine. The harness is the car, the road, and the traffic laws.
A couple of public numbers make this concrete. On Terminal Bench 2.0, one team moved a coding agent from outside the top 30 into the top 5 by changing only the harness, with the same model underneath. A separate experiment at LangChain added 13.7 points on the same benchmark by changing just the system prompt, tools and middleware around a fixed model. Neither touched the model.
So when an agent does something dumb, I’ve learned to debug the harness first. Usually it’s a missing tool, a rule I wrote too loosely, a guardrail I forgot, or a context window full of junk. Most agent failures are configuration failures. I find that encouraging, because configuration is the part I can fix today, without waiting for a better model. The model will get swapped out under the harness sooner or later anyway. I’ve written this up at more length as harness engineering and the factory model.
Context engineering is the part that decides your bill
If the harness is the system, context engineering is the most important knob inside it. The paper sorts agent context into six types: instructions, knowledge, memory, examples, tools and guardrails. The interesting decision, the one that shows up on your bill, is what goes in static versus dynamic context.
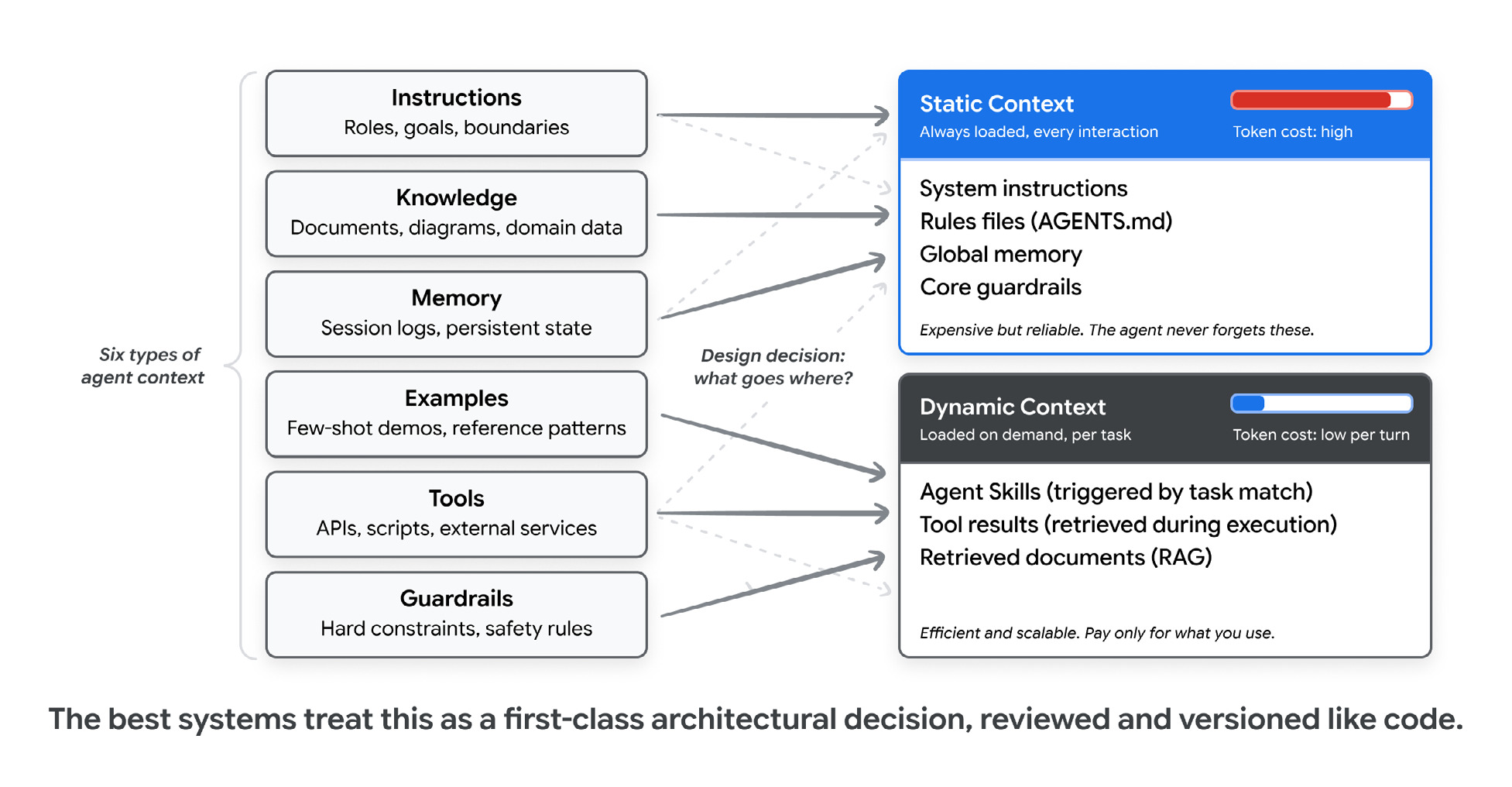 Static context is loaded on every turn, so it’s reliable and expensive. Dynamic context is loaded on demand, so you only pay for what a task needs.
Static context is loaded on every turn, so it’s reliable and expensive. Dynamic context is loaded on demand, so you only pay for what a task needs.
Static context is loaded every turn: system instructions, rule files (AGENTS.md, CLAUDE.md, GEMINI.md), global memory, core guardrails. It’s reliable, and it’s expensive, because you pay for it on every single call. Dynamic context is loaded on demand: skills that fire when a task matches, tool results, documents pulled from RAG. You only pay for the bits a given task touches.
Get that balance wrong in one direction and you burn tokens and bury the signal. Wrong in the other and the agent forgets the rules that keep it safe. The paper’s advice, which I agree with, is to treat the boundary as a real architectural decision: reviewed in a pull request, versioned like code.
The trick that makes dynamic context scale is Agent Skills with progressive disclosure. The agent sees a little metadata at startup, loads the full instructions when a task matches, and only pulls in the heavy reference material when it actually needs it. That’s how one agent can carry dozens of skills and still only pay for the one it’s using.
Verification is the line between vibe coding and engineering
You can sit anywhere on the spectrum from vibe coding to agentic engineering with the same agent. The thing that decides where you land is verification.
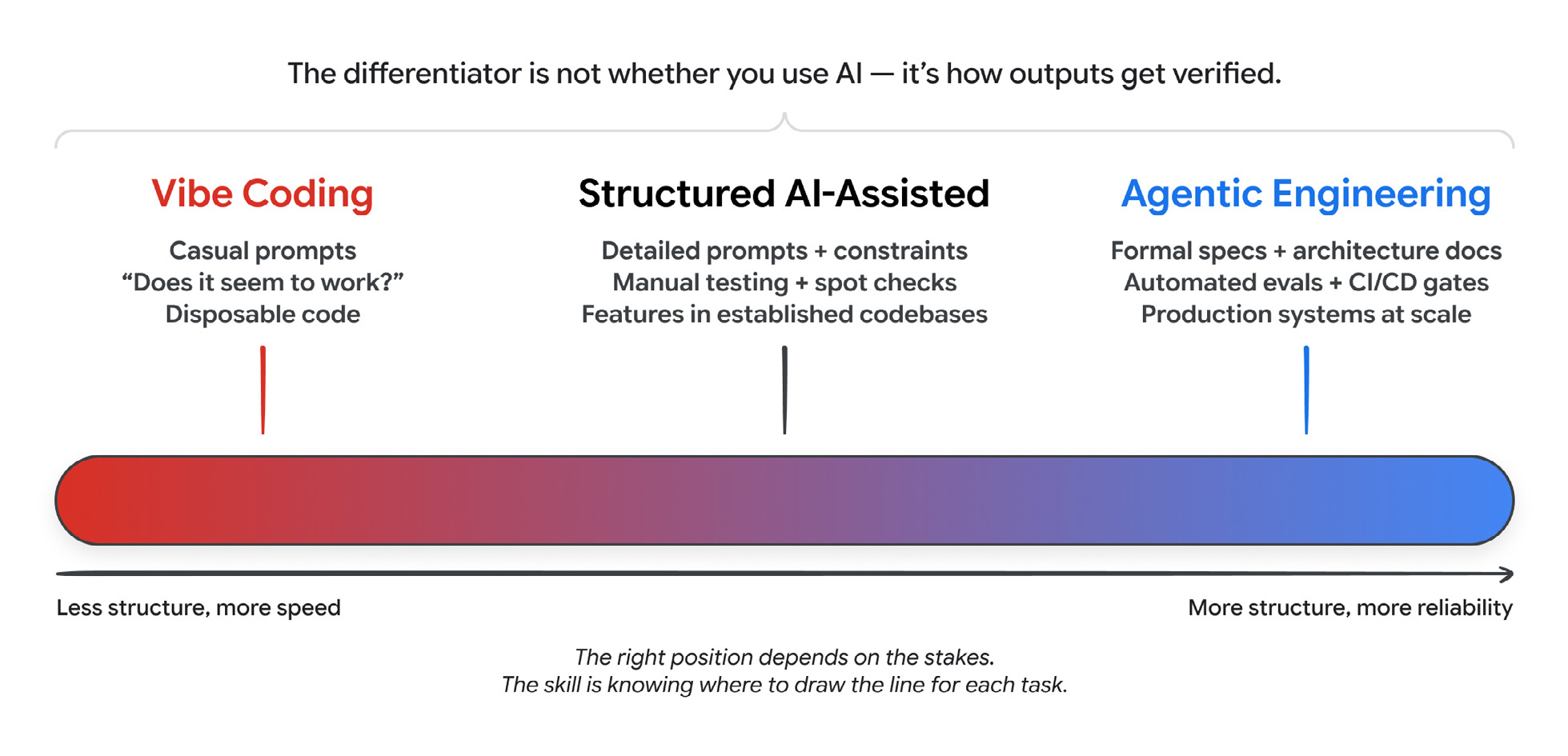 The right spot on the spectrum depends on the stakes. The skill is knowing where to draw the line for each task.
The right spot on the spectrum depends on the stakes. The skill is knowing where to draw the line for each task.
There are two mechanisms. Tests cover the deterministic parts: this input, that output. Evals cover the parts that aren’t deterministic, and the paper splits them in a way I found useful. Output evaluation asks whether the final result is correct. Trajectory evaluation asks whether the path it took to get there, the tool calls and the reasoning, was sound. You want both. An answer that looks right but skipped its checks is more dangerous than one that’s obviously broken.
If I had to hand a leader one line from the paper, it’s this: set the bar at the eval, not the demo. A demo shows an agent can work once. An eval suite with a real rubric shows it works reliably. I keep making this argument; see agentic code review.
How each phase actually changes
AI compresses the lifecycle, but unevenly, and the unevenness is the whole story. Implementation drops from weeks to hours. Requirements, architecture and verification stay slow, because they’re judgment work. So specification quality becomes the bottleneck, and verification moves to the middle.
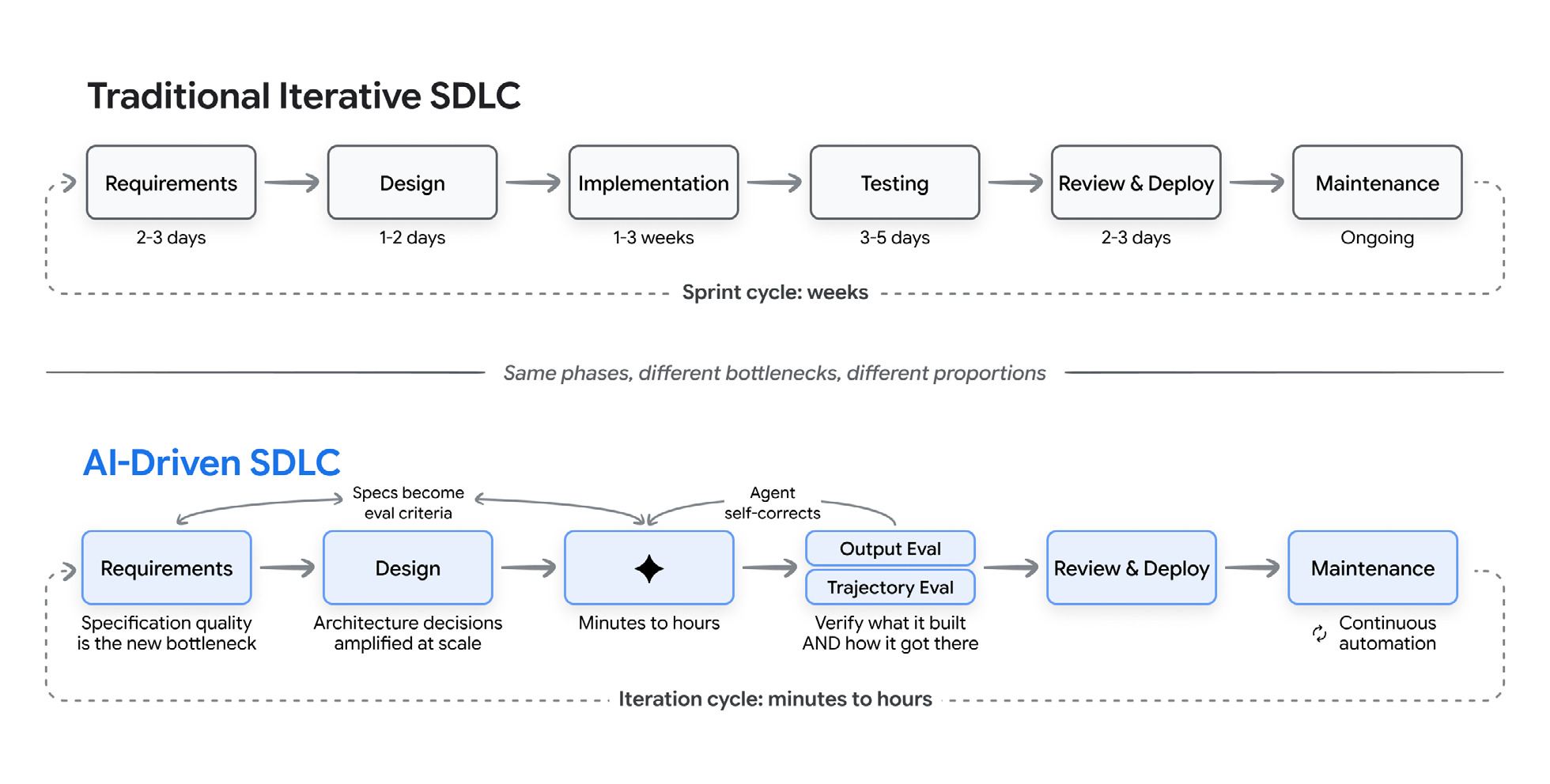 Same phases, different bottlenecks, different proportions.
Same phases, different bottlenecks, different proportions.
Phase by phase:
- Requirements stop being a document you hand between teams. They become a conversation that produces a spec and a first prototype at the same time. The agent drafts user stories from a brief, surfaces edge cases, and turns a description into something that runs in minutes.
- Architecture is the most stubbornly human phase. Trade-offs like consistency versus availability depend on business context the model can’t fully see. The developer’s job becomes making and documenting the structural calls the agent then implements.
- Implementation is where the gains and the caveats both live. Surveys put the productivity gain at 25 to 39%. A METR study found experienced developers going 19% slower on some tasks once you count the time spent checking and fixing. Both are true. The honest summary is that AI turns implementation from writing into reviewing.
- Testing and QA flips around. Your tests and evals become the main way you tell the agent what “correct” means, wired into a loop: run against a benchmark, cluster the failures, fix the prompt or tool that caused them, check against a regression suite, watch production for new ones.
- Maintenance is the one I think is most underrated. Code that was “too risky to touch” because only its authors understood it can now be read, refactored and modernized by an agent. The migrations and deprecation cleanups that never happened because they were tedious and risky start happening.
The ceiling on all of this is still the 80% problem: agents get the first 80% of a feature fast, and the last 20%, the edge cases and the seams between systems, still needs context the models usually don’t have.
The economics: context and routing are financial levers
The number that matters to a leader isn’t velocity, it’s total cost of ownership. The AI era splits it in a way that flips the usual intuition about which option is cheap.
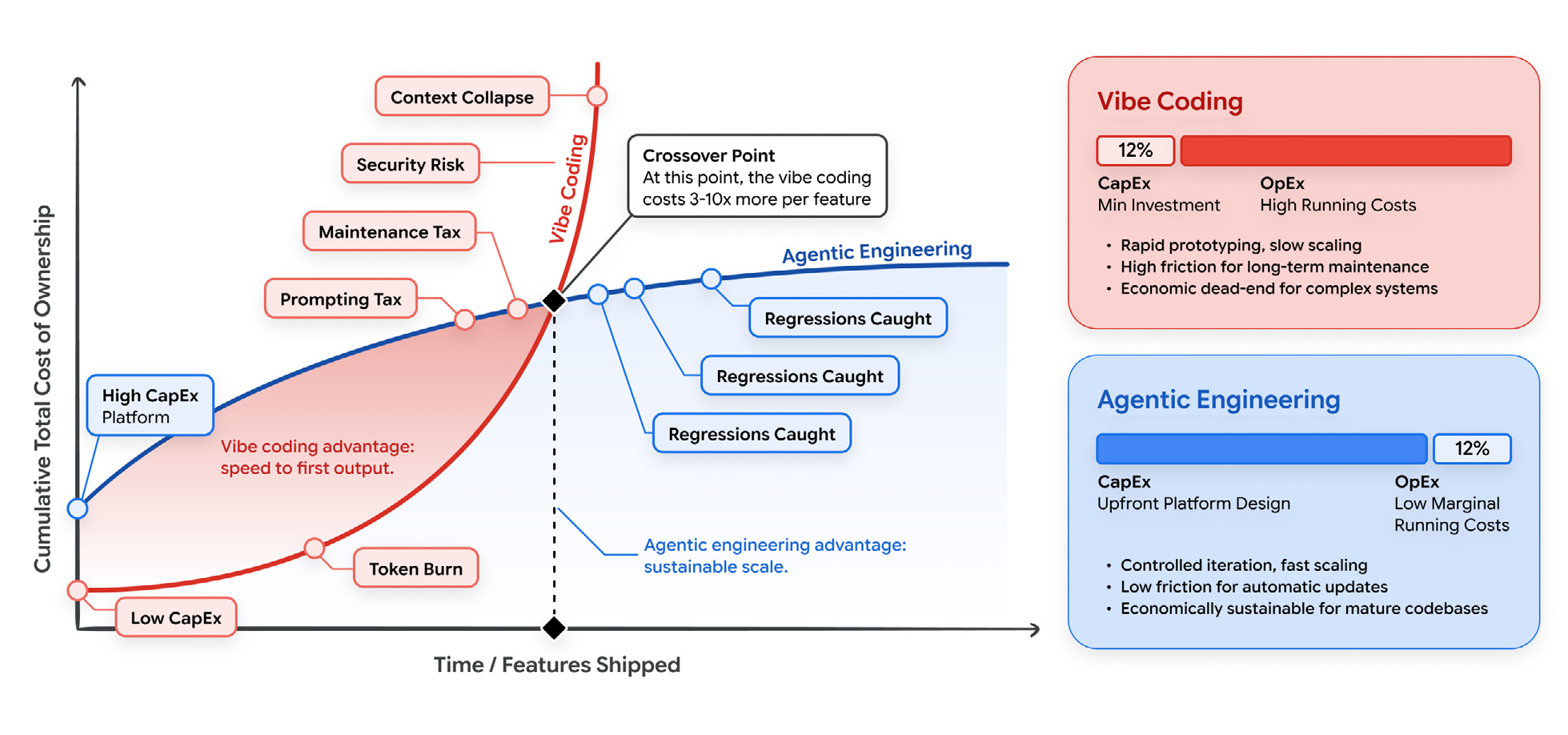 Past the crossover, vibe coding costs 3 to 10x more per feature. How long the code has to live decides whether you ever get there.
Past the crossover, vibe coding costs 3 to 10x more per feature. How long the code has to live decides whether you ever get there.
Vibe coding is cheap up front and expensive to run. You pay almost nothing to start: a subscription and some prompts. Then you pay later. Token burn, from throwing unstructured files at the model and asking it to fix its own mistakes. A maintenance tax, when someone has to reverse-engineer the ad-hoc code months later. Security cleanup, because fast generation produces vulnerabilities about as fast as it produces features. Agentic engineering flips that: more up front (schemas, tests, structured context), less per feature after.
The “vibe coding costs 3 to 10x more per feature” crossover is illustrative, not a measured constant. The part I want developers to take away is that context engineering and model routing are financial levers, not just technical ones. You can’t pass a 100,000-token repo into every prompt and expect it to scale. Route the hard reasoning to a big model and the routine work, test generation, code review, CI checks, to a small cheap one. The quality holds and the bill comes down. That’s the money side of what I’ve called the orchestration tax.
The prototype is becoming the production agent
This is the part of the paper I’m watching most closely. The same terminal workflow that spits out a throwaway script can now produce a production agent, in the same place, often by talking to the coding agent you were already using.
Building, evaluating and deploying a real agent, with persistent memory, scoped permissions, eval coverage and observability, used to be a separate stack and a separate job. Now it folds into the loop you already run. Google’s Agents CLI is built around this. After a one-time install, your coding agent picks up skills for the whole lifecycle, and you drive it in plain language:
# one-time setup
uvx google-agents-cli setup
# then, in your coding agent:
> Build a support agent that answers questions from our docs.
> Evaluate it on the FAQ dataset.
> Deploy it to Agent Engine.
Behind that one instruction it scaffolds the project, writes the code, generates an eval set, runs it, deploys to a managed runtime, and reports back. The prototype from your laptop yesterday becomes the production agent serving users today, with no rewrite. Coordination between agents runs on open standards: MCP for tools, A2A for handing work to other agents.
There’s one experiment in the paper I keep mentioning to people. An Anthropic team had a group of agents build a working C compiler in Rust over two weeks, with humans setting direction and reviewing rather than writing the code. That’s roughly the shape of where this is heading.
Day to day you switch between two modes the paper calls the conductor and the orchestrator. The conductor is real-time and in the IDE, keystroke by keystroke, good for exploring and for code you don’t know yet. The orchestrator is async: you hand a goal to one or more agents and review what comes back, good for well-specified work like migrations or test generation. The tooling does both now, sometimes in the same hour. I think the move from conductor to orchestrator is a skills shift before it’s a tooling one.
The figure for everyone else
One more figure, and this one isn’t for you. It’s for the people you’re trying to bring along: the exec who still thinks this is fancy autocomplete, the colleague who hasn’t made the jump.
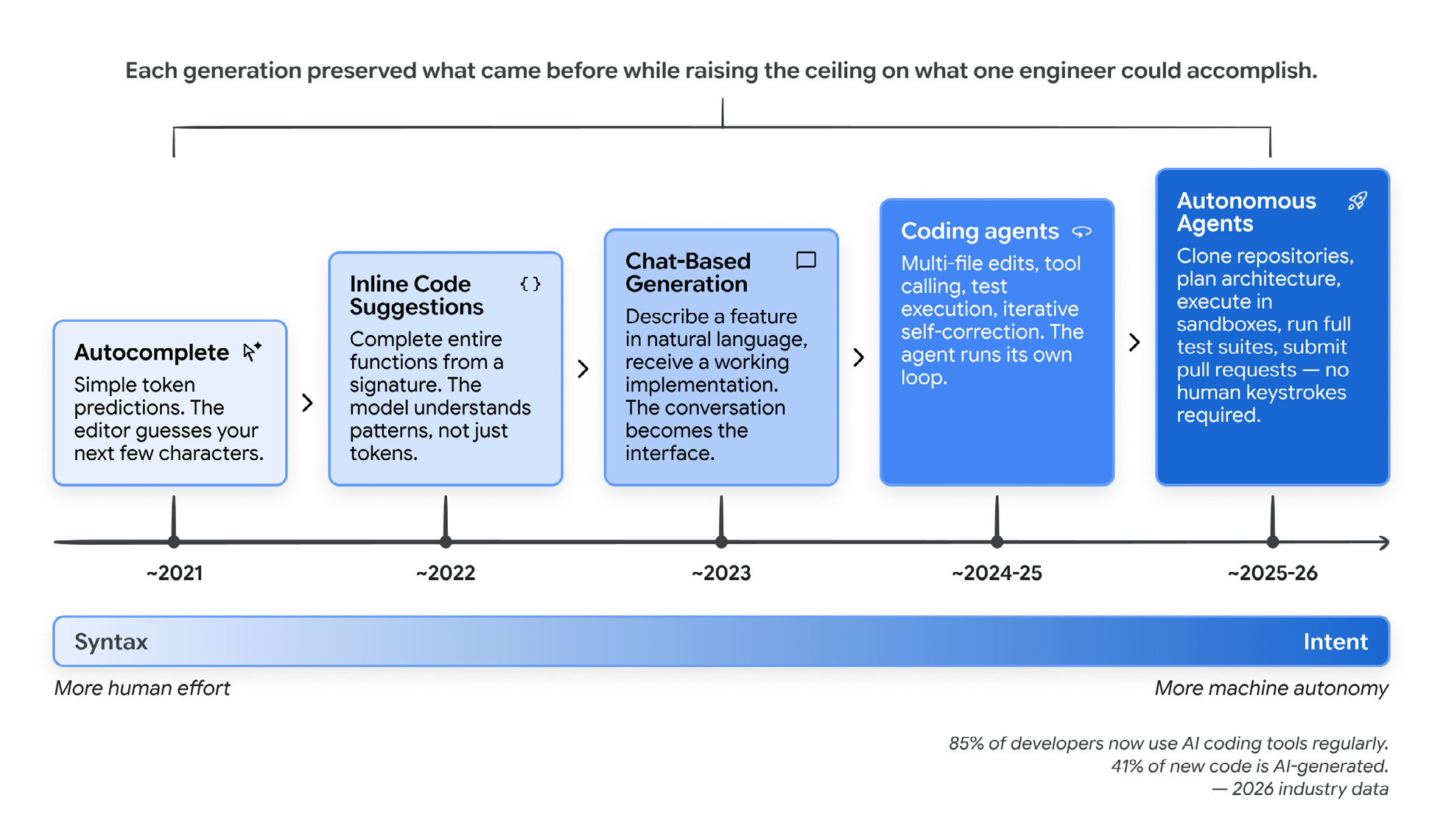 Each generation kept what came before and raised the ceiling on what one engineer could do.
Each generation kept what came before and raised the ceiling on what one engineer could do.
It has the adoption numbers that tend to end the “is this real yet” argument. As of early 2026, 85% of professional developers use AI coding agents regularly, 51% use them daily, and roughly 41% of new code is AI-generated.
Where to start
The paper closes with a longer set of recommendations for individuals, leaders and organizations. I won’t repeat them all here.
If there’s one line to take from it, it’s that AI amplifies whatever engineering culture it lands in, the good parts and the bad parts both. Generation is mostly solved now. The work that’s left is specification and verification, and the systems that hold them together. That’s the part I’d get good at.