Long-running Agents
April 28, 2026
A long-running AI agent can keep making progress over hours, days, or weeks. It can do this across many context windows and sandboxes, recover from failure, leave structured artifacts behind, and resume where it left off.
For two years the dominant image of an “AI agent” has been a chat window with a clever loop in it. You type a goal, the agent calls some tools, you watch tokens stream by, you stop watching when the work runs out of patience or the context window fills up. That paradigm got us a long way, but it has a ceiling. The model forgets. It declares “task complete” when it isn’t. It re-introduces a bug it fixed nine turns ago. The whole thing is structured around a single sitting.
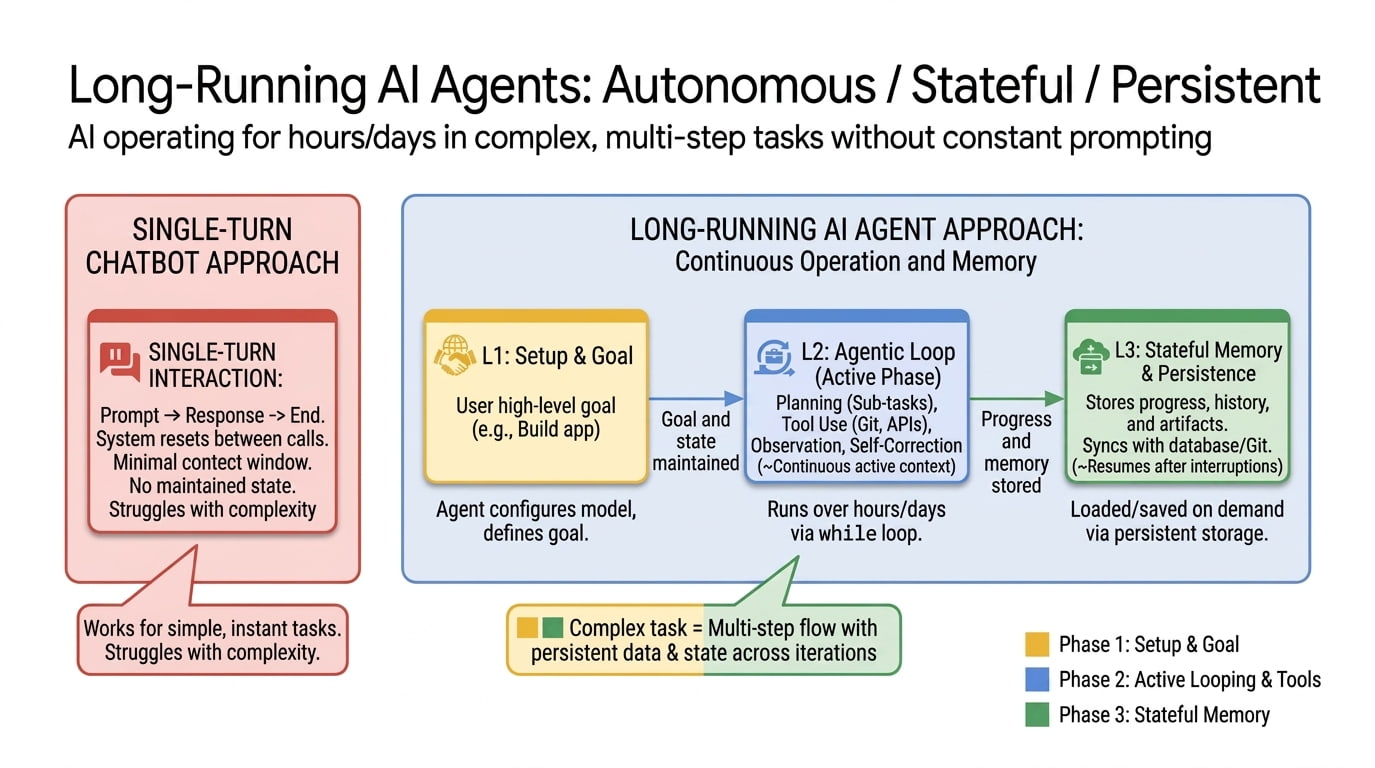
Long-running agents are what comes next. The idea is easy to state: an agent that keeps making forward progress on a goal across many sessions and many sandboxes, possibly many days or weeks, while leaving the workspace clean enough that the next session can pick up where the last one left off. The engineering is harder. You have to solve for persistence, recovery, and verification in a way that doesn’t just paper over the cracks. You have to build a state layer that lives outside the model’s context window, and you have to design the handoff between sessions so the agent doesn’t lose its mind when it wakes up and finds itself in a different sandbox with a different context window.
This post is my attempt to lay out what’s changed, who’s pushing on it, and how an engineer can use long-running agents today without writing the whole thing from scratch.
What “long-running” actually means
“Long-running” gets used to mean at least three different things in practice, and it helps to keep them separate.
Long-horizon reasoning. The agent has to plan and execute over many dependent steps. This is mostly a model-quality story: coherence, planning, the ability to recover from a wrong turn ten steps ago. METR has been tracking this with their time horizon metric, which estimates how long a task a frontier model can complete with 50% reliability. The headline finding is that the metric has been doubling roughly every seven months since 2019, and their TH1.1 update earlier this year doubled the count of 8-hour-plus tasks in the eval set. If that curve holds, frontier agents complete tasks at the day scale by 2028 and the year scale by 2034.
Long-running execution. The agent’s process runs for hours or days. Maybe it’s a coding job, maybe it’s a research sweep, maybe it’s a 24/7 monitoring service. The model might be invoked thousands of times across the run. This is mostly a harness story, and it’s the one this post is mostly about.
Persistent agency. The agent has an identity that outlives any single task. It accumulates memory, learns user preferences, and is always available. This is the Memory Bank flavor of long-running.
In practice the three blur together. A real production agent does long-horizon reasoning inside a long-running execution backed by persistent agency. But the engineering problems are different in each, and so are the products that solve them.
Why this matters
There are two reasons I believe this work matters a lot right now.
The first is a phase change in what’s economically feasible to delegate. An agent that runs for ten minutes can answer a question, summarize a doc, fix a small bug. An agent that runs for ten hours can own an entire feature, finish a migration that was on the backlog for six quarters, or do the kind of overnight research sweep that used to require a junior analyst. One of Anthropic’s Claude Sonnet announcements put concrete numbers on this last fall: 30+ hours of autonomous coding in internal tests, including one run that produced an 11,000-line Slack-style app. That’s already past the threshold where the answer to “should I delegate this?” is no longer obvious.
The second is that persistence changes what the agent is. A stateless agent answers your question and disappears. A long-running one accumulates context: which competitor moved which way last week, which test flaked twice on Tuesday, what you usually mean by “the dashboard.” Anthropic’s Project Vend was the most public early demonstration of this. They had a Claude instance run an actual office vending business for a month, managing inventory, setting prices, talking to suppliers. It failed in informative ways, and the second phase ran much better, but the point wasn’t profitability. The point was watching what kinds of weird coherence problems show up when an agent has to maintain identity across weeks instead of turns.
Those are the same problems every team building production agents now hits.
The three walls every long-running agent hits
Three walls show up in basically every write-up I’ve read this year.
Finite context. Even a 1M-token window fills. And context rot, the steady degradation of model performance as the window gets full, kicks in well before the hard limit. A 24-hour run is not going to fit in any context window the field has on its roadmap. Something has to give.
No persistent state. A new session starts blank. Anthropic’s framing in their scientific computing post is the cleanest version I’ve seen: “imagine a software project staffed by engineers working in shifts, where each new engineer arrives with no memory of what happened on the previous shift.” Without an explicit persistence story, every shift change is a productivity disaster.
No self-verification. Models reliably skew positive when they grade their own work. Asked “are you done?” they answer “yes” more often than they should. Without a separate signal that the work meets a bar, you get the agent that ships at 30% complete with full confidence.
Long-running agent designs are mostly answers to these three problems. The major labs have converged on similar shapes of answer, but with very different surface area.
The Ralph loop: one of the simpler practitioner versions of long-running agents
The Ralph loop (sometimes called the Ralph Wiggum technique) is one of “simpler” practitioner version of long-running agents, popularized by Geoffrey Huntley and Ryan Carson. The reference implementation is literally a bash script that loops:
- Pick the next unfinished task from a list (
prd.jsonor equivalent). - Build a prompt with the task, the relevant context, and any persistent notes.
- Call the agent.
- Run tests or other checks.
- Append what happened to
progress.txt. - Update the task list (done, failed, blocked).
- Go back to step 1.
The reason it works is the same reason any of the harnesses below work: state lives outside the agent’s context. prd.json is the plan, progress.txt is the lab notes, AGENTS.md is the rolling rulebook. The agent itself is amnesiac, but the filesystem isn’t. Each iteration starts fresh and reads enough state from disk to keep going. Carson’s Compound Product extends the idea by chaining multiple loops (an analysis loop that reads daily reports, a planning loop that emits a PRD, an execution loop that writes the code), which is roughly the open-source version of the planner-generator-evaluator triad Anthropic landed on independently.
I went deeper on all of this in Self-improving agents: task list structure, progress files, QA gates, monitoring, the failure modes you’ll actually hit. The short version is that you can build a working long-running agent in an evening with a bash script and a JSON file. Most of what Google and Anthropic have productized is the work of making this pattern recoverable, secure, and observable at scale.
The big-lab stories below are different ways of paying for that production-readiness.
Anthropic: harnesses, then the brain/hands/session split
Anthropic has been the most public about the engineering. Two posts are worth reading end-to-end.
The first is “Effective harnesses for long-running agents”, which lays out a two-agent harness for autonomous full-stack development. An initializer agent runs once at the start of a project to set up the environment, expand the prompt into a structured feature-list.json, and write an init.sh that future sessions will run on boot. A coding agent is then woken up over and over, each session asked to make incremental progress on one feature, run tests, leave a claude-progress.txt note, and commit. A test ratchet (“it is unacceptable to remove or edit tests because this could lead to missing or buggy functionality”) sits in the prompt to stop the very common failure of an agent deleting failing tests to “make them pass.” InfoQ’s writeup extends this into a planner, generator, and evaluator triad, on the same logic that separating generation from evaluation matters because models grade their own work too generously.
The second is “Scaling Managed Agents: Decoupling the brain from the hands”, the architectural post behind Claude Managed Agents (Anthropic’s hosted runtime, launched in early April). The argument is that an agent has three components that should be independently replaceable. The Brain is the model and the harness loop that calls it. The Hands are sandboxed, ephemeral execution environments where tools actually run. The Session is an append-only event log of every thought, tool call, and observation.
This sounds abstract and it isn’t. Anthropic’s framing: “every component in a harness encodes an assumption about what the model can’t do on its own.” When you couple them, an assumption that goes stale (e.g., the model used to need an explicit planner and now plans natively) means the whole system has to change at once. When you decouple them, the harness becomes stateless, sandboxes become cattle, not pets, and a brain crash doesn’t lose the run. A fresh container calls wake(sessionId) and reconstitutes the state from the log. They reported time-to-first-token dropped ~60% at p50 and over 90% at p95 just from being able to start inference before the sandbox is ready.
The session-as-event-log idea is the part most teams underappreciate. It is what makes a long-running agent recoverable. Without it, a container failure is a session failure and you’re debugging into a stale snapshot. With it, the agent’s memory is a queryable artifact that lives outside whatever process happens to be running at the moment.
For the scientific computing crowd, Anthropic’s long-running Claude post reduces all of this to a simpler stack: CLAUDE.md as a living plan the agent edits as it learns, CHANGELOG.md as portable lab notes, tmux plus SLURM plus git as the execution and coordination layer, and the Ralph loop, a for loop that kicks the agent back into context whenever it claims completion and asks if it’s really done. Their flagship case study is a Boltzmann solver Claude Opus 4.6 built over a few days that reached sub-percent agreement with a reference CLASS implementation. Months-to-years of researcher time, compressed.
Same patterns across all three posts: an explicit plan file, an explicit progress file, structured handoffs between sessions, separate generation from evaluation, and a loop that refuses to let the agent stop early.
Cursor: planners, workers, judges
Cursor’s “Scaling long-running autonomous coding” is the other essential read this year. They walked into walls that Anthropic mostly papered over.
Their first attempt was a flat coordination model: equal-status agents writing to shared files with locks. It became a bottleneck and made the agents risk-averse, churning rather than committing. Their second attempt swapped locks for optimistic concurrency control, which removed the bottleneck but didn’t fix the coordination problem. The third design is what’s running in production now and what they describe as solving most of the problem:
- Planners continuously explore the codebase and emit tasks. They can recursively spawn sub-planners.
- Workers are focused executors. They don’t coordinate with each other and they don’t worry about the big picture.
- Judges decide when an iteration is finished and when to restart.
Two things stand out from the post. One: “a surprising amount of the system’s behavior comes down to how we prompt the agents” more than the harness or the model. Two: different models slot into different roles. Their reported finding is that a GPT model was better than Opus for extended autonomous work specifically because Opus tended to stop early and take shortcuts. Same task, different role, different model. The matching is becoming part of the design surface.
This pairs with Composer 2 (their proprietary frontier coding model that ships in Cursor 3) and their background cloud agents: long-running tasks that run on Anysphere’s cloud infrastructure rather than your laptop. Eight-hour refactors and codebase-wide migrations survive a closed lid. You can start a task locally, hit run in cloud when you realize it’ll take 30 minutes, and re-attach later from your phone. Each agent runs in an isolated git worktree and merges back via PR. The handoff between local and remote is the part most teams haven’t figured out yet, and Cursor’s bet is that it has to be its own product surface.
The shape ends up close to Anthropic’s: roles are split, sessions are durable, judges sit beside the worker, and a long task runs in a cloud sandbox with git as the coordination substrate.
Google: long-running agents on the Agent Platform
Google’s announcement at Cloud Next ‘26 two weeks ago folded Vertex AI into the Gemini Enterprise Agent Platform and turned long-running agents into a named product, with named SLAs.
The pieces that matter for this post:
- Agent Runtime supports agents that “run autonomously for days at a time” with sub-second cold starts and on-demand sandbox provisioning. The launch post’s example use case is a sales prospecting sequence that takes a week to play out, which is roughly the right shape for it.
- Agent Sessions persist conversation and event history. You can pin them to a custom session ID that maps to your own CRM or DB record, so the agent’s state lives next to the business state instead of in a separate AI silo.
- Agent Memory Bank is the persistent long-term memory layer, generally available as of Next ‘26. It curates memories from sessions, scopes them to a user identity, and exposes a search API so the next agent invocation can pull what’s relevant. Payhawk reported that auto-submitting expenses through a Memory-Bank-backed agent cut submission time by over 50%.
- Agent Sandbox handles hardened code execution.
- Agent-to-Agent Orchestration, Agent Registry, Agent Identity, Agent Gateway, Agent Observability, and Agent Simulation cover basically every operational concern you’d otherwise build by hand for a production fleet, including the cryptographic-identity-and-audit-log story enterprises actually need to ship.
Architecturally this is the same brain/hands/session split Anthropic described, just productized at platform scale and bundled with ADK (the code-first dev kit) and Agent Studio (the visual one). If you’re building inside Google Cloud, you don’t have to design a session log or a memory store from scratch anymore. You wire an ADK agent into Memory Bank and Sessions, deploy onto Agent Runtime, and the persistence question is answered.
Notice how much this looks like the pattern Anthropic and Cursor describe, just unbundled into named services with SLAs. Three years ago you’d have built all of this yourself. Now you pick which version of “decoupled brain, hands, and session” you want to rent.
Five patterns for long-running agents in production
Shubham Saboo and I wrote up five design patterns we’ve seen separate working long-running agents from demos. They aren’t Google-specific, but they map cleanly onto the primitives Agent Runtime now exposes, so it’s worth walking through them here in shortened form.
Checkpoint-and-resume. The most common multi-day failure is context loss. An agent processes 200 documents over four hours, hits an error on document 201, and without a checkpoint you start from scratch. Treat the agent like a long-running server process: write intermediate state to disk, checkpoint every N units of work, recover from failures. The Agent Runtime sandbox gives you a persistent filesystem, but choosing the right checkpoint granularity (not every step, not only the end) is on you.
Delegated approval (human-in-the-loop). Most “human-in-the-loop” implementations are: serialize state to JSON, fire a webhook, hope someone responds. The state goes stale, the notification gets buried, the agent re-deserializes into a slightly different world. Long-running runtimes let the agent pause in place with full execution state intact: reasoning chain, working memory, tool history, pending action. Hours of human time pass, the agent consumes zero compute, and it resumes with sub-second latency. Mission Control is Google’s inbox for this. The pattern works regardless of vendor.
Memory-layered context. A seven-day agent needs more than session state. Memory Bank handles long-term curated memory, Memory Profiles add low-latency lookups, and the failure mode you’ll hit in production is memory drift: the agent learns a procedural shortcut from a few atypical interactions and starts applying it broadly. Govern memory like you govern microservices. Agent Identity controls who can read and write which banks. Agent Registry tracks which version of which agent is running. Agent Gateway enforces policy on the wire. The auditing question stops being “what are my agents doing?” and becomes “what are my agents remembering, and how is that changing their behavior?”
Ambient processing. Not every long-running agent talks to a human. Some sit on a Pub/Sub stream or a BigQuery table and act on events as they arrive: content moderation, anomaly detection, inbox triage. The architectural decision worth making early is to not hardcode policy into the agent. Define it in the Gateway and the fleet picks up policy changes without redeploys. Ambient agents run unsupervised for long stretches, and the only sane way to update a hundred of them is to update the policy layer once.
Fleet orchestration. In real systems, you rarely have one agent. A coordinator delegates sub-tasks to specialists (a Lead Researcher Agent, a Scoring Agent, an Outreach Agent), each running independently for different durations. Each specialist gets its own Identity (so the Outreach Agent can’t read financial data meant for Scoring), its own policy enforcement, its own Registry entry. This is the same coordinator/worker shape distributed systems have used for decades. What’s new is that ADK handles it declaratively with graph-based workflows, and a bad deployment in one specialist doesn’t cascade to the others.
The patterns compose. A compliance system might use checkpointing for document processing, delegated approval for review gates, memory layering for cross-session knowledge, and fleet orchestration to coordinate the specialists. The opening question is always the same: what’s the longest uninterrupted unit of work your agent needs to perform? Minutes, and you don’t need long-running agents. Hours or days, and these patterns are where to start. The full write-up with code samples covers each pattern in depth.
So how do you actually build one today?
This is the practical question and it has a different answer depending on what you’re building.
You’re a developer who wants long-running coding work on your own repo. Just use Claude Code (or Antigravity, Cursor, or Codex). The harness is already there. Treat your AGENTS.md like a pilot’s checklist: short, every line earned by a real failure. Add hooks for typecheck and lint that surface failures back to the agent. Write a plan file before the agent starts. Use the Ralph loop when the agent claims it’s done and you don’t believe it. For multi-hour or overnight jobs, run in a worktree so a closed laptop doesn’t kill the run, and have it commit progress every meaningful unit of work. This is the path most people should take, and it’s where the most leverage is right now.
You’re building a hosted agent product. Don’t build the runtime. Pick a managed one. The three real options today: Google’s Agent Platform (Agent Engine + Memory Bank + Sessions), Claude Managed Agents, or roll something on top of ADK, the Claude Agent SDK, or Codex SDK and host it yourself. The trade-off is the usual one. Managed gets you the brain/hands/session split, observability, identity, and an audit trail out of the box. Self-hosted gets you control and the ability to use weird models for weird roles (Cursor’s pattern). For most teams, the right starting point is a managed runtime plus your own ADK or SDK code for the actual loop.
You’re doing something autonomous and operational (monitoring, research, ops). Memory Bank-style persistence is what you want, and it’s the part that doesn’t exist in Claude Code. ADK + Memory Bank + Cloud Run + Cloud Scheduler is the cleanest stack I’ve seen for “agent runs every N hours, accumulates state, alerts on a threshold.” This is also where Cursor’s planner/worker/judge split starts to matter more than it does for IDE coding, because the work is genuinely parallel and the failure modes are different.
A few things matter regardless of which path you take.
Write down the done-condition before the agent starts. This is the single highest-leverage move for long runs. The Anthropic harness post calls it the feature list; Cursor calls it the planner’s task spec. Either way, it’s an external file with explicit, testable completion criteria, and it exists so the agent can’t quietly redefine done mid-run.
Separate the evaluator from the generator. Self-grading is the failure mode. A planner / worker / judge pipeline, or a generator / evaluator pair, is a real architectural pattern not a stylistic preference. Even if it’s the same model in different roles with different prompts.
Invest in the session log, not just the prompt. The append-only event log is what makes the agent recoverable, debuggable, and auditable. If you can’t reconstruct what the agent did in the last 24 hours from durable storage, what you have is a long-running shell script that happens to call an LLM, not a long-running agent.
Treat compaction and context resets as first-class. Anthropic is explicit that summarization-as-compaction wasn’t enough for very long jobs; they had to do full context resets where the harness tears the session down and rebuilds it from a structured handoff file. It is essentially how humans onboard a new engineer.
There are some real limitations right now
A few things are still genuinely unsolved.
Cost. A 24-hour run with a frontier model and a few tools is not cheap. Without budgets, circuit breakers, and a hard cap on tool spend, an agent can quietly burn through a week’s API budget in an afternoon. This is solvable, but it’s an explicit step you have to take.
Security. A long-running agent with API keys, cloud access, and the ability to run shell commands has a much larger attack surface than a chat session. The brain/hands separation pattern matters here too: credentials should be unreachable from the sandbox where model-generated code runs, which is one of the benefits Anthropic calls out for Managed Agents.
Alignment drift. Over many context windows, agents drift. The original goal gets summarized, then re-summarized, then loses fidelity. This is the part hooks and judges exist to defend against. It is also the most common reason “the agent went off and did something I didn’t ask for.”
Verification. Auditing 24 hours of autonomous activity is a real human-time problem. Observability and structured artifacts (PRs, commits, briefings, test runs) are how you make this tractable. Without them, you’re scrolling logs and you’ll miss what matters.
The human role. This is the one I keep coming back to. Defining work crisply enough that an agent can run for a day on it is harder than doing the work yourself. The skill that’s appreciating in value isn’t writing code. It’s writing specs that survive contact with an autonomous executor.
Where this is going
Google, Anthropic, and Cursor have converged on roughly the same shape. Separate the model loop from the execution sandbox from the durable session log. Split planning from generation from evaluation. Bake in compaction, hooks, and context resets. Expose memory as a managed service that any agent invocation can query.
Surface area is what differs. Google’s Agent Platform is the enterprise-stack version, with the identity and audit trail story baked in. The patterns underneath are the same. Claude Managed Agents is “Anthropic’s harness, hosted.” Cursor’s background agents are “long-running coding, pulled out of the IDE and into the cloud.”
The harder problems for the next year aren’t in any of those layers individually. They’re in the coordination above them. Many long-running agents on a shared codebase. Agents that read their own traces and patch their own harnesses. Harnesses that assemble tools and context just-in-time for a task instead of being pre-configured at startup. That’s where the agent stops looking like a smarter chat window and starts looking like a colleague who’s been on the project longer than you have.
The model is still load-bearing. But the gap between a chat window and an agent you can leave running overnight is mostly in the state, sessions, and structured handoffs wrapped around it. That’s where I’d spend my learning time right now.
If you want the prerequisite reading, my Agent Harness Engineering post covers the harness primitives this one builds on, and Self-improving agents goes deeper on the Ralph loop pattern.