What's New in Gemini 3.0
November 25, 2025
On November 18 we shipped Gemini 3 Pro live across Google AI Studio, the Gemini app, Vertex AI, Search’s AI Mode, Google Antigravity, and more. We have been working on this release for a while, and I wanted to write down what actually shipped last week, how it all fits together, and what it unlocks for developers.

TL;DR: With Gemini 3.0, we pushed three big things out the door at once:
- a major upgrade in core reasoning and multimodal intelligence,
- a new generation of agentic coding capabilities (from Antigravity to the Gemini CLI), and
- a new image model, Nano Banana Pro, that finally makes “AI as design partner” feel real.
Gemini 3 Pro vastly outperforms 2.5 Pro on benchmarks, handles million token multimodal contexts, ships day one into multiple Google products, and powers an agent‑first IDE plus a much more capable CLI.
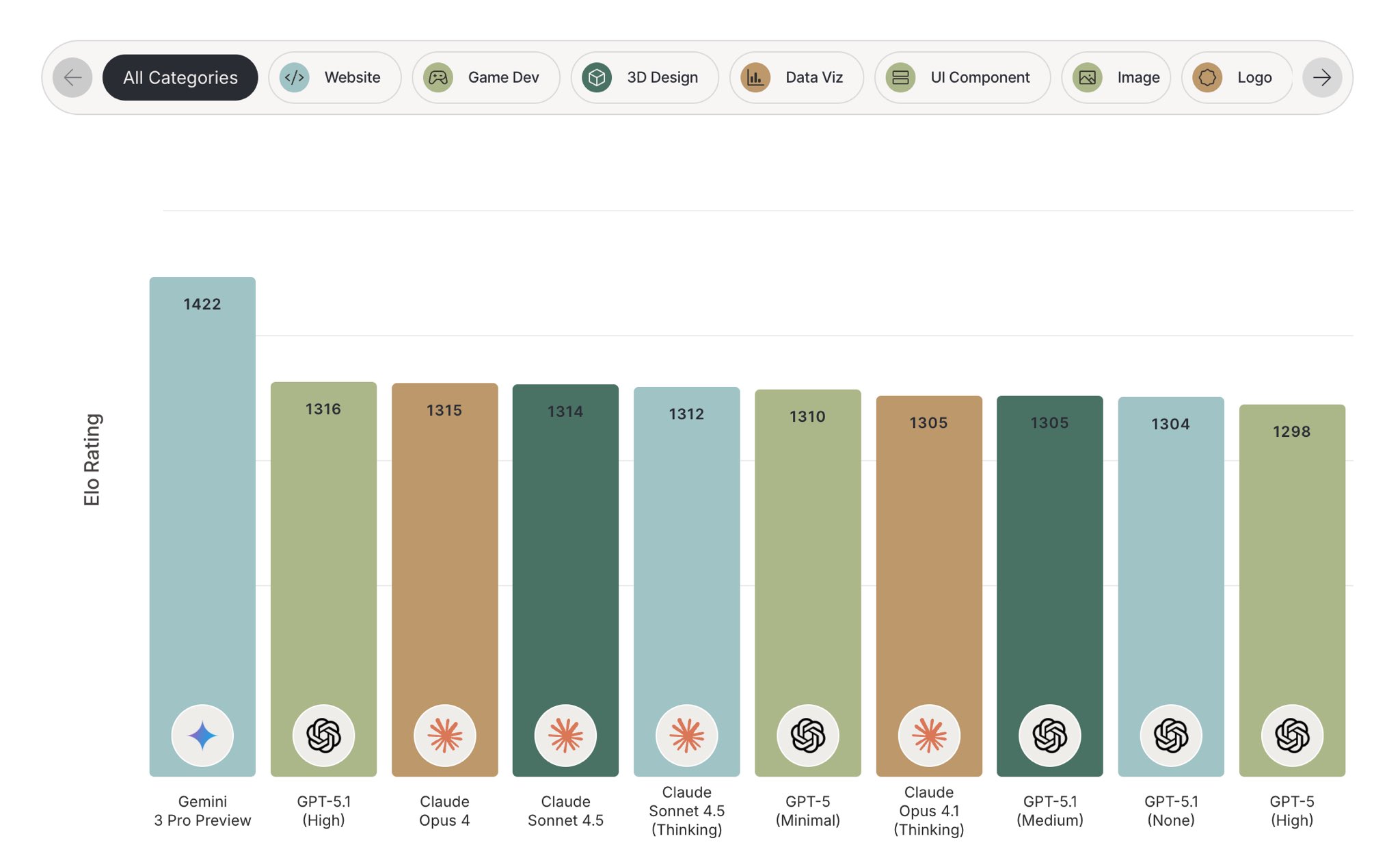
On coding and generative‑UI benchmarks like WebDev Arena and Design Arena, it sits at or near the top – I will drop a chart of its Design Arena performance alongside this post. Nano Banana Pro rides on top of that stack to give you precise, consistent, high‑resolution image generation and editing.
Below is the inside‑out recap of what we actually launched and what I am most excited about.
Gemini 3.0: A Quantum Leap in Intelligence and Integration
When we started planning Gemini 3, we had a very clear internal goal: ship our most capable model everywhere on day one, not just in a playground. On November 18, Gemini 3 Pro became the centerpiece of that strategy, going live in Search’s AI Mode, the Gemini app, Google AI Studio, Vertex AI, and more at Google scale from the moment we announced it.
Under the hood, Gemini 3 Pro is built on a trillion‑scale Mixture‑of‑Experts architecture with a 1 million token context window. That means you can throw entire repositories, long research papers, or multi‑hour transcripts (with images or diagrams mixed in) at a single prompt and have the model reason across all of it at once rather than chunking and stitching.
One of the big shifts from the previous generation is how deeply multimodal the core transformer is. We do not bolt on a separate vision model anymore. Text, images, audio, video, and code are all first‑class tokens going through the same reasoning core. In practice, that makes cross‑modal reasoning much more natural: you can hand the model a mix of code, screenshots, error logs, diagrams, and a spec, and it will treat that as one coherent problem instead of separate tracks.
From my vantage point inside the team, two things really stand out.
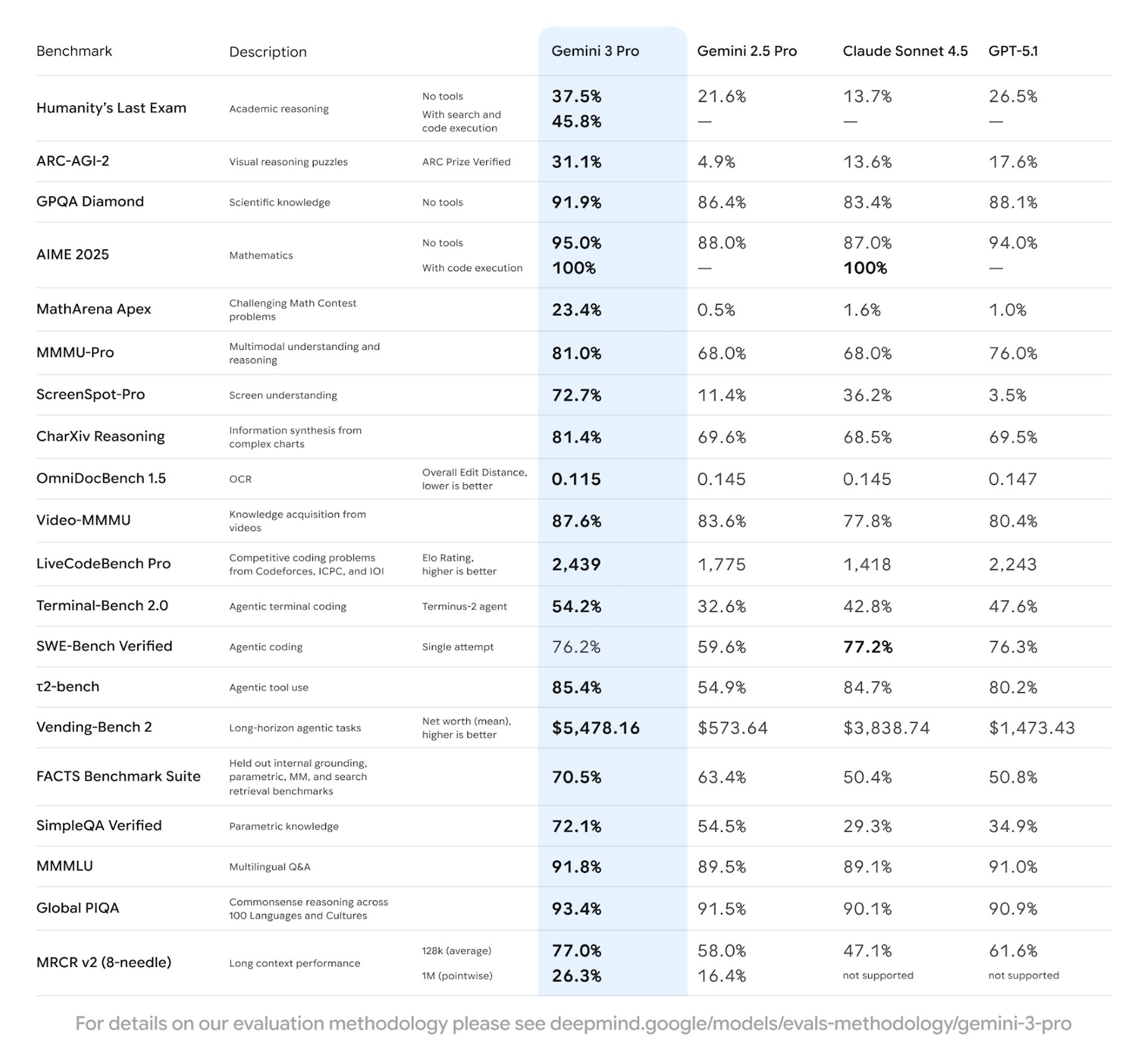
First, the jump in raw reasoning. Gemini 3 Pro significantly outperforms Gemini 2.5 Pro on every major benchmark we track internally. It tops LMArena (Chatbot Arena) with an Elo around the 1500 mark, retakes the lead on Humanity’s Last Exam (HLE) with mid‑30 percent scores and pushes even higher in the Deep Think configuration, and posts state‑of‑the‑art results on GPQA Diamond and MathArena Apex. That last one matters a lot to us, because high‑difficulty math has historically exposed fragility in reasoning. With 3.0, we see it solving Olympiad‑style questions that 2.5 simply could not do without heavy scaffolding.
It is not just academic. On benchmarks like SimpleQA Verified, which are closer to everyday factual question‑and‑answer, we see clear improvements in accuracy and a reduction in confabulations. Internally, the difference feels like moving from “smart chatbot that sometimes vibes” to “assistant that actually thinks through hard problems.”
Second, the way it “reads the room.” Compared to 2.5, 3.0 is much better at picking up context and intent. Long, messy prompts with half‑formed ideas, screenshots, links, and a few sentences of “here’s what I am trying to do” are now handled much more gracefully. It is also much better at choosing the right response form: sometimes that is text, but often it is code, a diagram, a draft UI, or an interactive snippet.
You can see this show up in product.
- In Search’s AI Mode (for Pro and Ultra subscribers), Gemini 3 does more than summarize. Ask about a physics concept and it can give you an interactive explanation with visuals or small simulations, not just a wall of text.
- In the Gemini app (formerly Bard), conversations feel more grounded and less brittle. Longer threads keep their intent better.
- We are also previewing Gemini 3 Deep Think for Ultra, which runs a heavier configuration for very hard problems. Internally we use this for things like automated research and complex planning; it pushes scores even higher on exams like HLE and ARC‑AGI‑2, but more importantly it just fails less on the genuinely nasty prompts.
The key point: this is not just a model quietly sitting behind an API. We shipped Gemini 3 Pro directly into the products people use every day, and we designed our developer tooling around it from day one. That is where the coding and agentic story comes in.
Next‑Level Coding: Vibe Coding, Benchmarks, and Agentic Skills
One of the bets we made early on in Gemini 3’s roadmap was that natural language as the primary programming interface would go from “demo” to “default” for a lot of workflows. Internally, we call this vibe coding: you describe the vibe of what you want, and the model figures out the implementation.
With Gemini 3 Pro, that finally feels real.
You can now take a prompt like “build me a futuristic nebula dashboard in dark mode, responsive, with a live data panel and a small chart editor” and the model will often generate a working frontend, sensible layout and styling, API calls wired up to mocked or real endpoints, and sometimes even basic tests in a single shot. With 2.5 Pro, we could do pieces of this, but it usually took multiple iterations and a lot of manual steering.
Above is my walkthrough of our improved design capabilities in Gemini 3 Pro.
We see that reflected in benchmarks that we and the community care about. In WebDev Arena, Gemini 3 Pro now sits at the top of the leaderboard for end‑to‑end web app creation from natural language specs. In Design Arena’s website generation challenges, human raters consistently prefer Gemini 3’s outputs for both quality and faithfulness to the spec. On SWE‑Bench (Verified), pass‑at‑1 jumps significantly over 2.5 Pro on real‑world GitHub issues. On Terminal‑Bench 2.0, Gemini 3 scores in the mid‑50 percent range on tool‑use and Linux terminal tasks, which is a good proxy for “can this model actually drive a computer reliably.”

On more traditional coding benchmarks, we are roughly at parity with other frontier models on the standard problem sets. The difference shows up in the hard stuff and long‑horizon tasks. On adversarial or contest‑style coding (think Codeforces‑style LiveCode benchmarks), Gemini 3 Pro’s Elo is notably higher than the previous generation. And in design‑oriented evaluations like Design Arena, we see that when developers are asked to choose between model outputs, they pick Gemini 3’s work more often.
From the inside, the biggest day‑to‑day change is how agentic the coding experience has become.
Gemini 3 is much better at breaking a vague request into concrete subtasks, choosing when to call tools (repositories, terminals, browsers, search, custom APIs), executing those steps, and checking its own work. That is why in the Gemini 3 for developers post you will see us describe 3.0 as the best vibe‑coding and agentic‑coding model we have built so far. In practical terms, it behaves less like a code autocomplete and more like a junior engineer who can read the codebase, propose a plan, implement it, run tests, and come back with diffs and logs.
Developers can tap into this in a few ways.
- Through the Gemini API in Google AI Studio and Vertex AI, Gemini 3 Pro is available with pricing tuned so that you can actually use it for serious workloads, plus a free tier in AI Studio so you can experiment without worrying about cost.
- In build mode in AI Studio, you can literally type “make me a retro 3D spaceship game” and watch the app materialize as the model generates and wires everything together.
All of this is the foundation for Antigravity, which is where we lean fully into agent‑first workflows.
Google Antigravity: An Agent‑First IDE for the Gemini Era
Antigravity is the tool that made this whole launch week feel different inside Google.
Instead of shipping yet another “chat on the side of your editor,” we shipped an agent‑first IDE where Gemini 3’s coding agents are first‑class citizens. You can read the full announcement on the Antigravity developer blog, but the short version from my experience is simple: it changes how you think about an IDE.
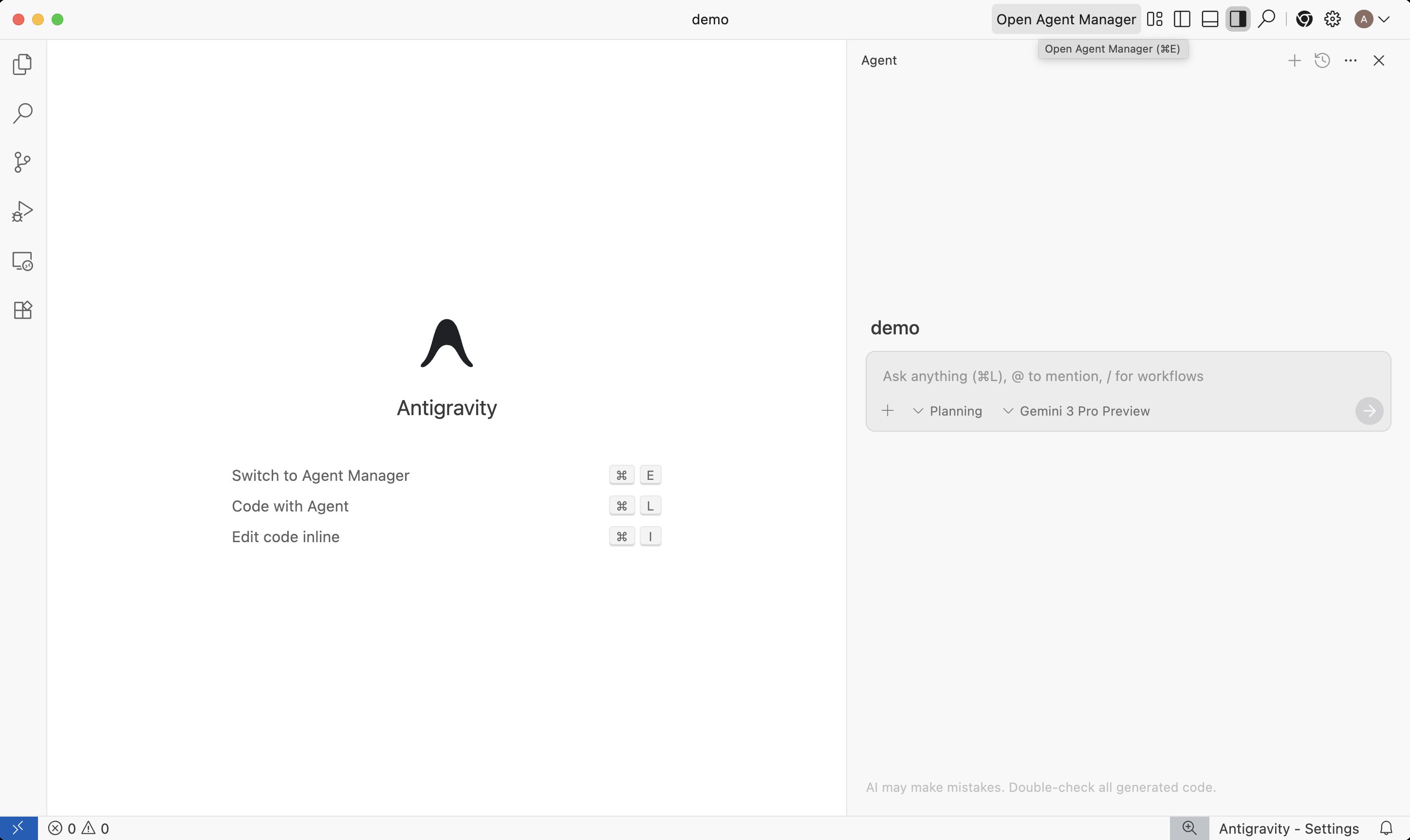
The core idea is straightforward.
You still have a familiar editor view for writing and reviewing code. Alongside it, you get a manager surface where you spin up and supervise agents. Those agents have direct access to the editor, an integrated terminal, and a built‑in browser.
So you might say: “Add a dark mode toggle to settings, use a moon icon, persist the user preference, and write tests.” From there, an agent will plan the work as a set of subtasks, edit files in your repo, run commands in the terminal, open the browser preview to visually verify the change, and iterate until it believes the task is done.
What you see is not a raw token stream. You see artifacts: task lists and plans, diffs and test results, screenshots or recordings of the app after changes. This artifact system is critical. Instead of scrolling through a giant log, you review a human‑readable trail of what the agent did, almost like a junior dev documenting their steps. If the dark mode toggle looks wrong, you comment on the artifact (“use a different icon,” “make the background slightly lighter”), and the agent goes back and fixes it.
A few things I personally like about Antigravity.
It cuts out context switching. I am not juggling between editor, terminal, browser, and docs. The agent is allowed to drive those tools, and I stay at the level of intent and review. Agents can work in parallel – one can refactor a legacy component while another adds tests or updates documentation – and you see their progress in the manager surface like a little mission control. And while Gemini 3 Pro is the star, Antigravity is designed to support other models too, so you are not locked in if you want to experiment.
Antigravity is in free public preview right now, available on Mac, Windows, and Linux. If you spend a lot of your day in an IDE, it is worth installing just to internalize what an agent‑first workflow feels like. My experience so far is that prompts shift from “write a function that…” to “build a feature that…”, and that is a bigger jump than it sounds.
Gemini 3 plus Antigravity can already handle front‑to‑back tasks: plan, code, run, verify, and present the result in a way that is actually inspectable. It still needs human oversight, but the amount of manual glue code and yak‑shaving it eliminates is very real.
Gemini 3 in the Terminal: Upgrading the CLI and Code Assist
Not everyone wants an IDE. A lot of us live in the terminal, which is why we also launched a much more capable Gemini CLI and upgraded Gemini Code Assist around 3.0.
The Gemini CLI is an open‑source terminal agent that embeds Gemini directly into your shell. You can find the project on GitHub and in the Gemini CLI docs. With Gemini 3 behind it, the CLI can read and edit files in your repo, propose and run shell commands (with your confirmation), generate or refactor code, and help with environment setup, builds, and deployments.
The new piece we added here is a stronger client‑side Bash tool plus a complementary server‑side tool. In plain terms, this means the model does not just tell you “run this command”; it can actually execute those commands in your terminal, see the output, and react. Ask “spin up a Flask app and run it,” and it can scaffold the project, install dependencies, start the server, and then help debug if something fails.
Gemini Code Assist brings the same brain into your existing tools. In editors like VS Code and Android Studio, Code Assist (described at codeassist.google) can now see a far larger context thanks to the 1M token window. That makes whole‑repo reasoning, smarter code review, and better refactors possible. In team and enterprise settings, it can sit across your monorepo, understand your internal libraries, and give much more tailored suggestions.
The Terminal‑Bench 2.0 results I mentioned earlier are not abstract for me; you feel them when you ask the CLI to do something non‑trivial like “find all TODOs in this project, classify them by type, and propose fixes for the highest‑impact ones.” Gemini 3 in the terminal will actually walk the tree and locate TODO comments, cluster them into themes, draft code or migrations for the ones that matter, and offer to apply and test them.
This is a very different experience from the earlier generation of AI shell helpers, which were mostly glorified prompt generators for common commands.
All of this is available with a generous free tier, which was important to us. We want this to be something you can just add to your daily workflow, not a tool you worry about “saving tokens” for.
We are also careful about safety here. The CLI will ask for confirmation on destructive actions, and Gemini 3 includes stronger protections around tool use and prompt injection. But the core idea remains simple: your terminal now has an intelligent collaborator that can actually do work, not just explain it.
Nano Banana Pro: Gemini’s Image and Design Model Goes Turbo
On the visual side, the other big launch this week was Nano Banana Pro, our new image generation and editing model built on Gemini 3 Pro.
Internally we think of Nano Banana Pro as Gemini 3’s visual cortex. It takes the reasoning and world knowledge of the core model and applies it directly to images. The result is an image system that is finally good enough to use not only for pretty pictures but for real design and product work. You can see the public overview in the Nano Banana Pro announcement and the Gemini 3 Pro image model page.
Above is my walkthrough of Nano Banana Pro’s new image generation and editing capabilities.
Here is what feels new from my perspective working with it.
Nano Banana Pro is not just “type a prompt, get an image.” It is a full editing tool that you can drive with language. You can do masked edits to change specific regions of an image while preserving the rest, adjust lighting, color grading, and time of day across a scene, change aspect ratio while intelligently expanding or trimming the scene, and control depth of field, focus, and other photographic cues.
For example, I can take a daytime room photo and say “turn this into an evening scene with warm lighting and deeper shadows,” and the model will update the whole mood while keeping geometry and objects consistent. Or I can extend a square product shot into a wide banner, and it will expand the background without warping the subject. In earlier generations, these kinds of tasks usually meant bouncing to a raster editor. Now you can stay in the Gemini flow.
Because Nano Banana Pro is built on Gemini 3, it shares its language understanding. That means you can issue fairly complex prompts and get back something close to what you imagined on the first try. Things like “create a four‑panel noir storyboard: establishing city shot, hero close‑up, action moment on a rooftop, and a cliffhanger frame, with the same character and monochrome style across all panels” are now within reach. In practice, this means less time prompt‑engineering and more time exploring.
One of the biggest pain points with earlier image models was consistency. You could generate a nice character once, but it was hard to keep them stable across multiple shots or scenes. Nano Banana Pro is specifically tuned for this. It can maintain consistent looks for multiple distinct characters or people and keep track of a set of objects or reference elements in a scene. That makes a huge difference for storyboards, marketing campaigns, and app illustrations. You can design a mascot once and then reuse it in a series of contexts. Or you can build a product hero shot and then place that same product in different environments without it morphing.
Because the model shares Gemini 3’s reasoning and knowledge, it can also generate infographics, diagrams, UI mockups, and other structured visuals that are grounded in facts or in a source document you provide. We have been using it to turn dense technical docs into architecture diagrams or sequence charts, handwritten notes into clean flowcharts, and textual descriptions of screens into UI mockups you can iterate on. The text rendering is much more reliable now, including for multiple languages, which has been a long‑standing annoyance in generative images.
We also pushed fidelity and resolution much higher. Nano Banana Pro supports outputs up to 4K in the API and pro tools, with 2K available in many consumer surfaces. The underlying upscaler and diffusion stack are tuned for detail retention at these resolutions. On top of that, you get robust cleanup tools: remove unwanted objects and fill backgrounds intelligently, tweak small imperfections, and use inpainting to surgically change parts of an image (swap colors, add a logo, remove a shadow).
For a smart‑home product launch, for example, you can generate the hero product shot, ask Nano Banana Pro to insert your exact logo text cleanly, generate multiple environment shots (kitchen, living room, night scene) with the same device design, output banner and poster variants at different aspect ratios and resolutions, and do final cleanup in the same system instead of exporting to another editor.
You can access Nano Banana Pro today in the Gemini app by selecting the image creation mode and the “Thinking” model, inside Search’s AI Mode, via the Gemini API and AI Studio, and in other products like Ads creative tools, Slides, and our video tooling as those integrations roll out. All images from our tools carry SynthID watermarks to make their AI origin detectable, which is important as we move toward more powerful visual models.
Bringing It All Together
From the inside, this past week has felt like a turning point.
Compared to Gemini 2.5 Pro, Gemini 3.0 gives us a much stronger reasoning core, deeper multimodality with a huge context window, significantly better coding and tool‑use behavior, an agent‑first IDE in Antigravity, a genuinely capable terminal agent in the Gemini CLI, and a visual model, Nano Banana Pro, that turns Gemini into a real design and image editing partner.
We did not want this to be just another model release. That is why we shipped 3.0 straight into Search, the Gemini app, AI Studio, Vertex AI, Antigravity, Code Assist, and the CLI all in the same week. The goal is simple: wherever you build or explore ideas, Gemini 3 should be there, and it should feel like a capable collaborator, not a novelty.
For developers, this changes the texture of day‑to‑day work. You can vibe‑code entire apps from a description and then iterate with an agent that can actually run and debug the code. You can let agents handle the boring glue work while you focus on architecture and product decisions. You can generate and refine visual assets from the same system that writes your backend and your frontend. And you can wire all of this into your own tools with the Gemini API.
We are still early. There are rough edges, there are things Gemini still gets wrong, and human review remains essential. But after working on Gemini 3 and using it across Antigravity, the CLI, and Nano Banana Pro over the last week, it is hard to go back. It feels less like asking a chatbot for help and more like collaborating with a set of specialized, fast, tireless teammates.
If you build software, design experiences, or just like to push on what AI can do, this is the moment I have been waiting to share: Gemini 3.0 is out, it is topping benchmarks like WebDev Arena and Design Arena on the coding and UI side, and it is ready to build with you.