An Engineer's Guide to AI Code Model Evals
July 25, 2025
Improving a coding-capable AI model (like Google’s Gemini or OpenAI’s code models) is not as simple as just feeding it more data or tweaking some parameters. A crucial part of the process is evaluation – often abbreviated as “evals”. In the context of AI models, evals refer to structured tests or benchmarks we use to measure a model’s performance on specific tasks. For software engineers and web developers who are not AI specialists, it helps to think of evals as analogous to unit tests or integration tests in software: they define what “correct” or “good” looks like for the model’s outputs, so that we can systematically verify improvements (or detect regressions) as we refine the model.
In this deep dive, we’ll explore what evals are, how they’re constructed (including the idea of “goldens” or golden examples), what “hill climbing” means in model development, and how all these pieces connect to continuously training and improving coding models. We’ll use an example scenario of improving a model’s full-stack web development abilities (e.g. generating React/Next.js code) to illustrate these concepts. Let’s start by understanding why evals are so essential in the first place. The learnings here are roughly based on our experience developing Gemini coding capabilities at Google.
Why do we need evals for Coding models?
When you develop traditional software, you likely write tests to ensure your code works as intended. Similarly, AI models – especially large language models (LLMs) that generate code – need tests to measure how well they perform coding tasks. Unlike a simple deterministic program, an AI model’s output can vary and may be nondeterministic, so we need a robust way to define and detect a “good” solution. This is what AI evaluations (AI Evals) provide: a set of criteria and test cases that let us quantify the model’s capabilities.
For coding models, evaluations typically focus on functional correctness – does the model-generated code actually solve the problem? This usually means running the code and seeing if it produces expected results or passes all unit tests for a given prompt. For example, OpenAI’s HumanEval benchmark provides programming problems and a set of hidden tests for each; a model “passes” a problem if the code it generates produces the correct outputs for all those tests. Over time, code evals have evolved: early benchmarks like HumanEval and MBPP - Mostly Basic Python Problems Dataset - a benchmark of around 1,000 crowd-sourced Python programming problems - used simple single-function tasks and introduced the Pass@k metric (does at least one out of k generated solutions pass the tests?). This was analogous to running multiple solutions and seeing if any work, which is useful since these models can output several different attempts.
Crucially, without evals, we’d have no objective way to know if a new version of the model is actually better at coding than a previous version. Evals allow teams to track progress: “Our pass rate jumped from 70% to 85% on our test suite after this update” is meaningful evidence of improvement. They also help catch regressions – cases where a model update unintentionally gets worse on some tasks. In short, evals are the feedback loop that guides model development, much like tests guide software development.
What exactly do evals look like for Code Generation?
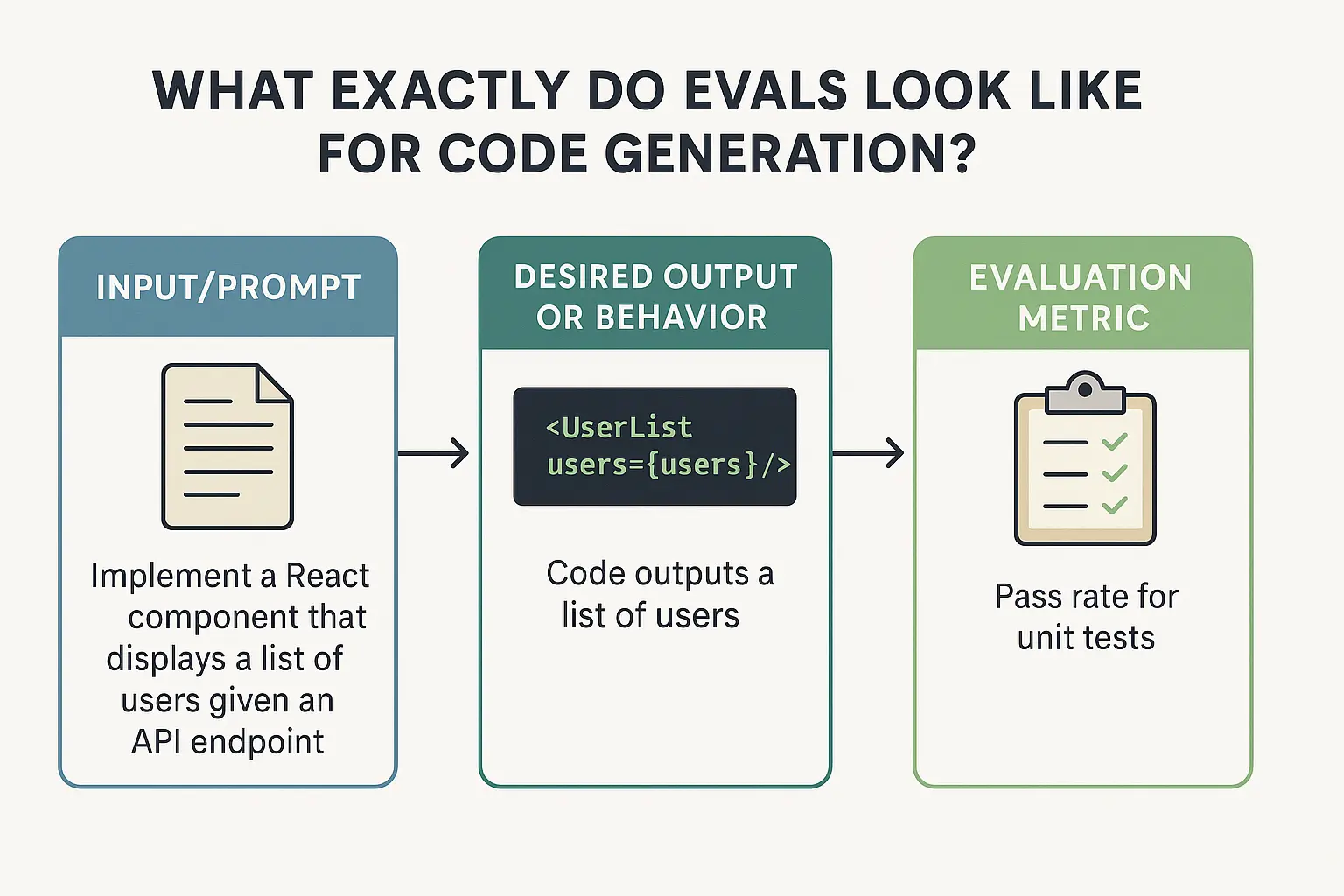
A good eval for a coding model is essentially a collection of programming tasks with clear success criteria. These tasks can range from very small (write a function to calculate Fibonacci numbers) to very realistic (fix a bug in a multi-file React application). Each task in an eval typically includes:
-
Input/Prompt: A description of the problem or a snippet of starter code (for instance, a prompt might be: “Implement a React component that displays a list of users given an API endpoint.”).
-
Desired output or behavior: This could be an explicit expected output (like a reference solution’s code, sometimes called a golden solution), or more often for code, a set of tests or criteria that the output must satisfy. In traditional terms, the golden represents what a perfect answer would produce.
-
Evaluation metric: A way to compare the model’s output to the expected outcome. For code, the primary metric is usually pass rate – does the model’s code pass all the unit tests for the task. For other aspects, metrics could include similarity to the golden solution or style correctness, but functional correctness is king.
Evals can be automated. For coding tasks, automation is straightforward by running tests. Many evaluation harnesses will execute the model’s generated code in a sandbox (like a Docker container) to verify it meets the requirements. Some evals might also include static analysis (checking code style, security, etc.) as part of the scoring.
Modern comprehensive benchmarks go beyond just “does it run” – they assess if the code integrates well with existing code, handles multi-file projects, uses APIs correctly, and follows good engineering practices. For example, the SWE-bench benchmark uses real-world coding challenges (like adding a feature to a production codebase) to evaluate models. In one SWE-bench example, a model had to add retry logic to a database connection function while preserving existing timeout logic, adding proper logging, and not breaking any integration testsi.
This is a far more complex eval task than a standalone algorithm puzzle, reflecting real software engineering work. Impressively (and a bit worryingly), even very large models have a long way to go on such real-world engineering tasks, according to SWE-bench results. This shows how challenging these evals can be – and why they’re so valuable for pushing model improvements.
Autoraters have become essential for scaling code evaluation beyond human capacity. An auto‑rater is typically a large language model prompted or fine‑tuned to evaluate another model’s outputs—acting as an automated substitute for human evaluators. It may use the same flagship model architecture (e.g. Gemini) with a detailed evaluation system instruction, rather than being a separately trained evaluator model, though in some cases organizations do train a specialized model for high‑fidelity evaluation These models are trained on massive datasets of human judgments. Autoraters can assess code for functional correctness, style adherence, security vulnerabilities, and maintainability, while providing detailed explanations for their judgments and confidence scores. This automation reduces evaluation time from weeks to hours while maintaining high agreement with human raters.
In summary, a coding eval defines “what good looks like” for the model’s output in a given scenario. By running an eval suite, we can quantify things like “Model X solves 80 out of 100 test problems correctly, while Model Y solves 85/100.” With that knowledge, let’s see how we actually use these evals to improve the model.
The “Hill Climbing” approach to improving models
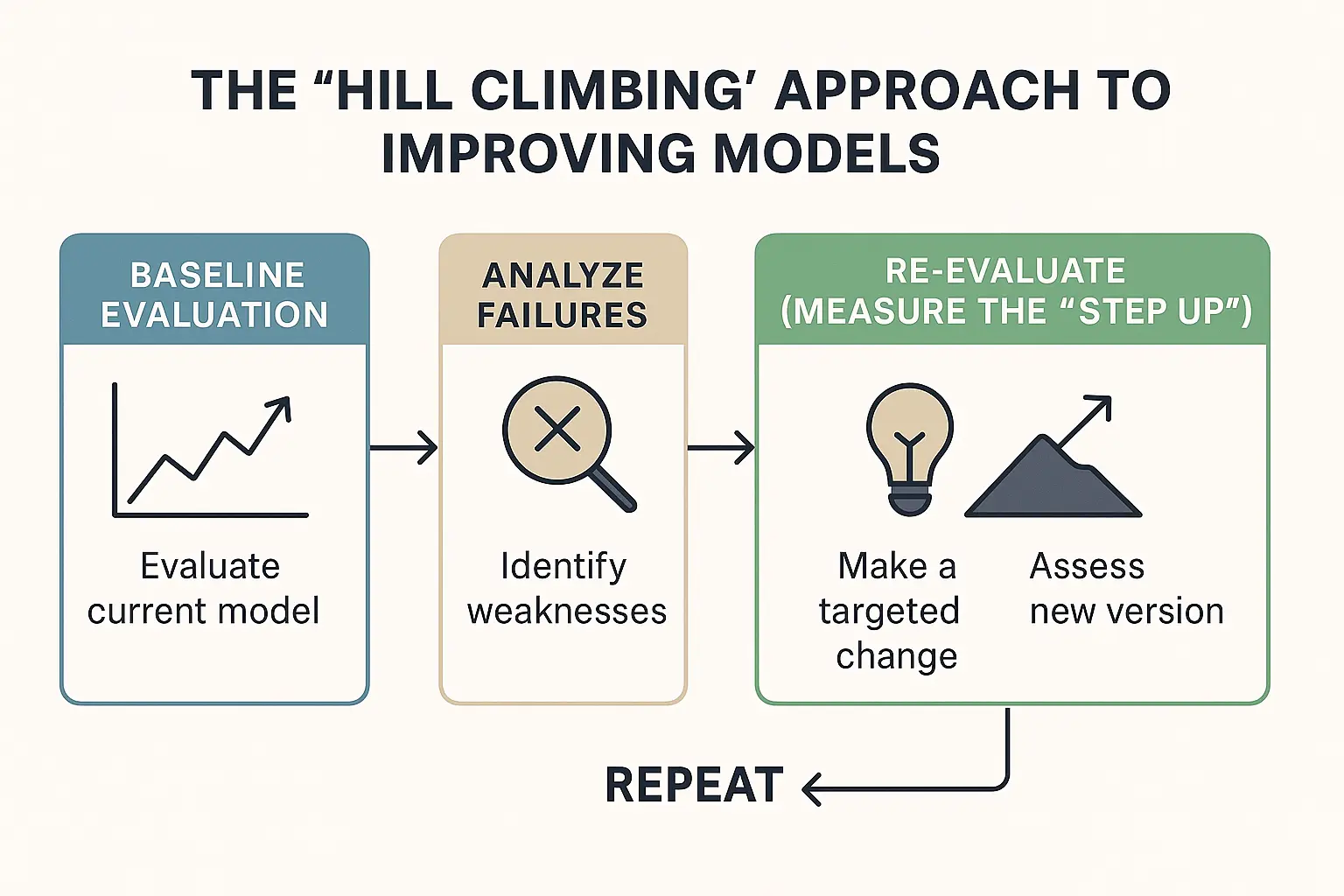
Having a suite of eval tasks is only half the story – the other half is what you do with that information. This is where the concept of “hill climbing” comes in. In an AI development context, hill climbing refers to an iterative, incremental improvement process guided by eval results. The term is inspired by an optimization algorithm that “starts with an initial solution and iteratively improves upon it”. Think of each model version as a point on a landscape, where the “height” is how well it performs on your eval metrics. You want to climb uphill – increase the scores – by making changes to the model or training process.
Hill climbing with evals works like this in practice:
-
Baseline evaluation: First, you thoroughly evaluate your current model on the full suite of tasks. This gives you a baseline score and identifies specific weaknesses. For example, you might find your model fails most tasks that involve Next.js API routes or struggles with CSS-in-JS styling.
-
Analyze failures: Treat the model’s failures like bug reports. Why did it fail a given task? Maybe it didn’t know a certain library function, or it produced incorrect syntax, or it misunderstood the requirements. This analysis can be done by inspecting outputs or using an automated judge model (an LLM-as-a-judge to score outputs), but often developer insight is crucial.
-
Propose an improvement: Once you see patterns in failures, make a targeted change. This could be adding training examples of the failing type (e.g., fine-tune the model on more React code if it’s failing React tasks), adjusting the model architecture, or even adding a prompt enhancement. For instance, if the model forgets to use React hooks correctly, you might include more examples of proper hook usage in its fine-tuning data.
-
Re-evaluate (measure the “Step Up”): After the change, run the same evals again on the new model version. Did the scores improve? For example, maybe now it passes tests for some of the Next.js tasks it failed before – an increase in the pass rate. If yes, you’ve moved up the hill (your model is better on those metrics). If the score stayed the same or worsened, that change didn’t help (or introduced regressions).
-
Repeat: Incorporate the lessons and continue with further tweaks. Each successful iteration ideally moves the model closer to the summit (the best possible performance on your evals).
This hill climbing process is an experimental loop. It’s very similar to agile development cycles or the scientific method: implement a change, measure results, learn, and iterate. By focusing on leading metrics (immediate eval improvements) you drive towards your lagging metric (overall model quality).
A concrete example in our full-stack web scenario: suppose evals show the model often fails to properly configure Next.js pages with data fetching (like getServerSideProps). On inspection, you find it usually forgets to export the function or uses it incorrectly. As an improvement, you fine-tune the model on a small set of correct Next.js examples and also add a rule in the prompt like “Remember to include required Next.js data-fetching methods when applicable.”
After this, re-run the eval tasks that involve Next.js. If the model now passes those tasks, you’ve climbed higher – maybe your Next.js-specific pass rate went from 40% to 80%. That’s a clear win. You would continue this process for other types of tasks (perhaps the model still struggles with CSS-in-JS or database integration – those become the next targets).
Importantly, this highlights that what we’re really optimizing may be the combination of model + tooling or system instruction, not just the model itself. If the goal is purely to improve model quality independently of tooling or prompting, then fine‑tuning alone is sufficient. Prompt‑level adjustments are a valid external layer of quality control when evaluating your entire code generation toolchain, but if your evaluation framework measures only model intrinsic capability, the focus should remain on training or fine‑tuning the model, not prompt engineering.
It’s worth noting a couple of cautions during hill climbing:
-
Avoid overfitting to the eval: If you tailor your model too much to the specific eval tasks (for example, by training on them directly or excessively focusing only on them), you might get a high score without truly making the model better in general. This is analogous to students who memorize answers to past exam questions – they ace the test but might not actually understand the material. In AI, this can happen if eval data leaks into training or if you excessively optimize on a fixed eval set. Researchers have found evidence that many code models were inadvertently trained on popular benchmark problems like HumanEval and MBPP, making their scores less trustworthy. To mitigate this, ensure your evals are fresh (not part of the training data) and consider having a diverse or rotating set of tasks.
-
Local vs Global optima: Hill climbing (the algorithm) can sometimes get stuck in a local maximum – an intermediate solution that’s better than nearby tweaks but not actually the best overall. In model development, this means you might make changes that improve one metric while unknowingly hurting another important capability. It’s crucial to monitor a broad range of evals. For coding models, that might mean tracking not only your specialized web dev tasks but also general coding tasks to ensure you didn’t break something the model used to do well. In practice, teams maintain a suite of evals covering different areas (algorithms, web, APIs, etc.) so they can catch if an improvement in one area caused a regression elsewhere.
Hill climbing is essentially an ongoing optimization process guided by evals. It embodies the principle “you improve what you measure.” If we measure well (with relevant evals) and iterate, the model should keep getting better on those measures.
What are “Goldens” and how do they fit in?
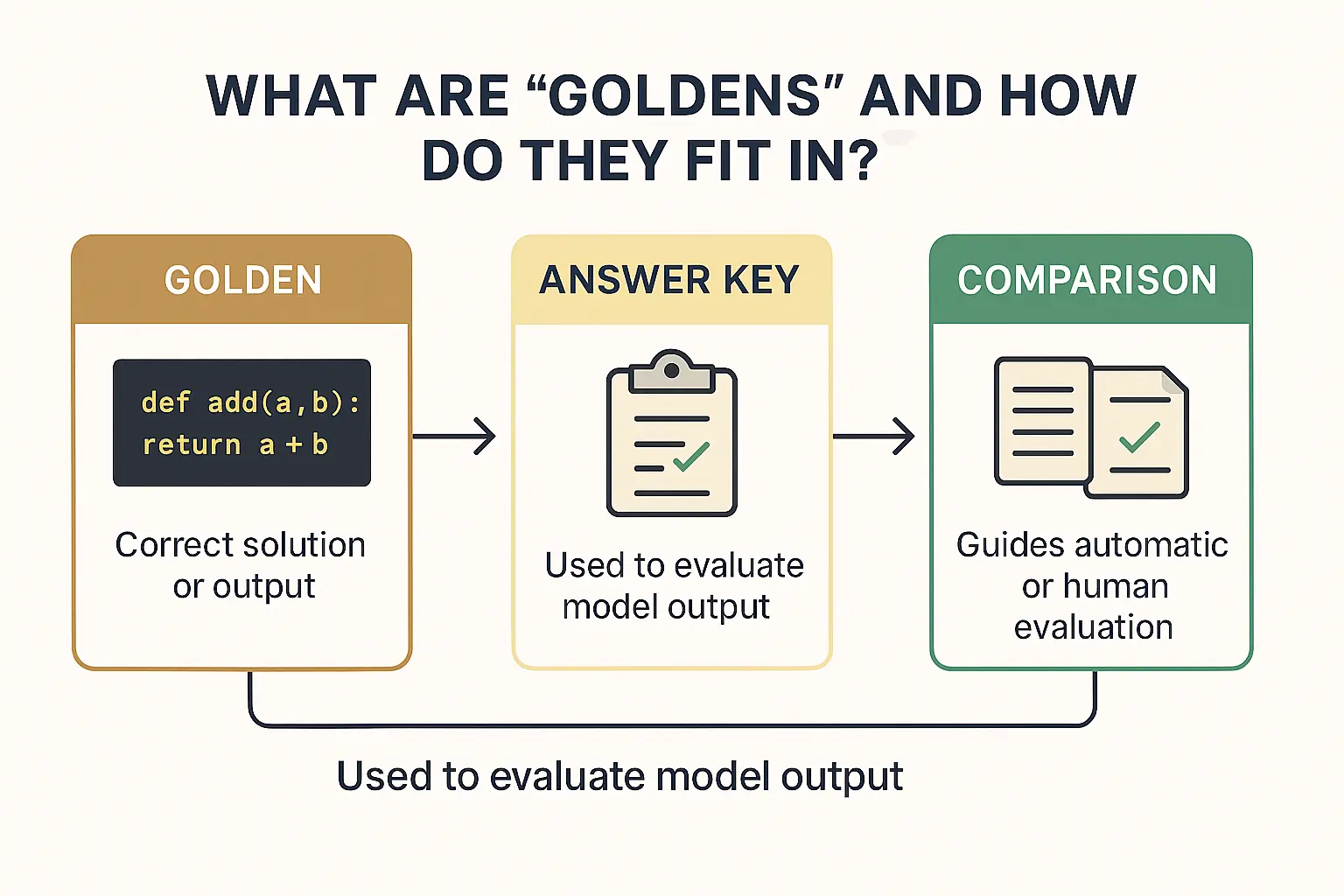
Throughout this discussion, we’ve mentioned goldens – short for golden examples or golden outputs. A “golden” is basically a ground-truth reference for an eval task: it’s what the ideal, correct model output would be for a given input. In the context of coding tasks, a golden could be a reference implementation of the solution (a correct code snippet), or simply the expected behavior (like the outcomes of the unit tests which the reference solution passes).
Think of goldens as the answer key for your eval. Just as a teacher’s answer key has the correct answers to exam questions, goldens specify what the model should produce (or how it should behave) for each test query. In an AI eval, before you even run the model, you (or domain experts) must define what counts as a correct or high-quality response. For a customer support chatbot, a golden answer might be a perfectly crafted, helpful reply to a user question. For a coding model, a golden might be a correctly implemented function or a patch that resolves a bug.
How do we use goldens? In two main ways:
-
Automatic grading: If we have a golden output, we can have the computer compare the model’s output to it. The simplest form is an exact match check – not very useful for code, since code can be correct even if not textually identical to the golden solution. More commonly in coding evals, we derive tests from the golden solution. For instance, if the golden code is the correct implementation, we can run the model’s code and the golden code on the same test cases and see if they behave the same. In more open-ended tasks, companies build auto-raters that compare AI outputs to goldens in a more abstract way For example, an auto-rater might check if all key elements present in the golden answer also appear in the model’s answer.
-
Guiding Human Evaluation: Sometimes, especially for qualitative aspects (like code readability or style), you might show a human evaluator the model’s output and the golden output for comparison. The golden serves as a benchmark for the evaluator to decide how close the model came to the ideal. Even large-scale eval frameworks sometimes use an LLM as a judge to compare the model’s output to a golden, scoring it for relevance or correctness.
In practice, constructing good goldens is a bit of an art. You need to ensure the golden output is truly high-quality and correct, otherwise you’re measuring against a flawed standard. Typically, goldens are written or verified by subject matter experts. In our full-stack web example, a golden for a Next.js feature task would be a robust implementation by a senior web developer that meets all requirements (e.g., correct use of Next.js APIs, proper error handling, etc.). That golden implementation can then be used to write test cases or as a reference for comparison.
Goldens connect to the training/improvement process directly. When your model fails on a task, examining the golden solution can reveal what it should have done. You might incorporate the golden solution into your model’s training data (a form of targeted fine-tuning), essentially teaching the model the correct approach. This must be done carefully – if you directly train on all your eval goldens, you risk overfitting (the model might just memorize those solutions). But selectively, feeding some goldens back into training can help fix specific weaknesses. Some teams follow a practice of “error-driven training”: take instances the model got wrong, add the question + golden answer to the next training round, thereby closing the loop. Over time, this can significantly improve performance on those types of problems.
Another role of goldens is in slicing and understanding model performance. By labeling parts of your eval dataset (for example, flag which tasks involve React useEffect vs. Next.js routing vs. database access), and having gold-standard answers for each, you can see where the model struggles the most. Perhaps it passes all the UI rendering tasks (golden outputs involving React components) but fails many data fetching tasks (goldens involving API calls). This insight guides you on what data to collect or what changes to make next.
To recap, goldens are the expected answers for your evals, providing a basis for scoring and a target for the model to aim for. Without goldens (or some form of ground truth), you can’t quantify how far off the model’s output is. They are the backbone of any reliable evaluation. As one product lead quipped, “Before testing, define what good outputs look like” – in other words, set up your goldens first.
Example: Improving Full-Stack web development skills of a model
Let’s tie everything together with an example scenario. Imagine we have a code generation model (say, a variant of GPT specialized for coding) and our goal is to make it excel at full-stack web development tasks. Specifically, we want it to handle modern frameworks like React (for the frontend) and Next.js (a popular React framework for server-side rendering and API routes). How do we approach evals and improvement?
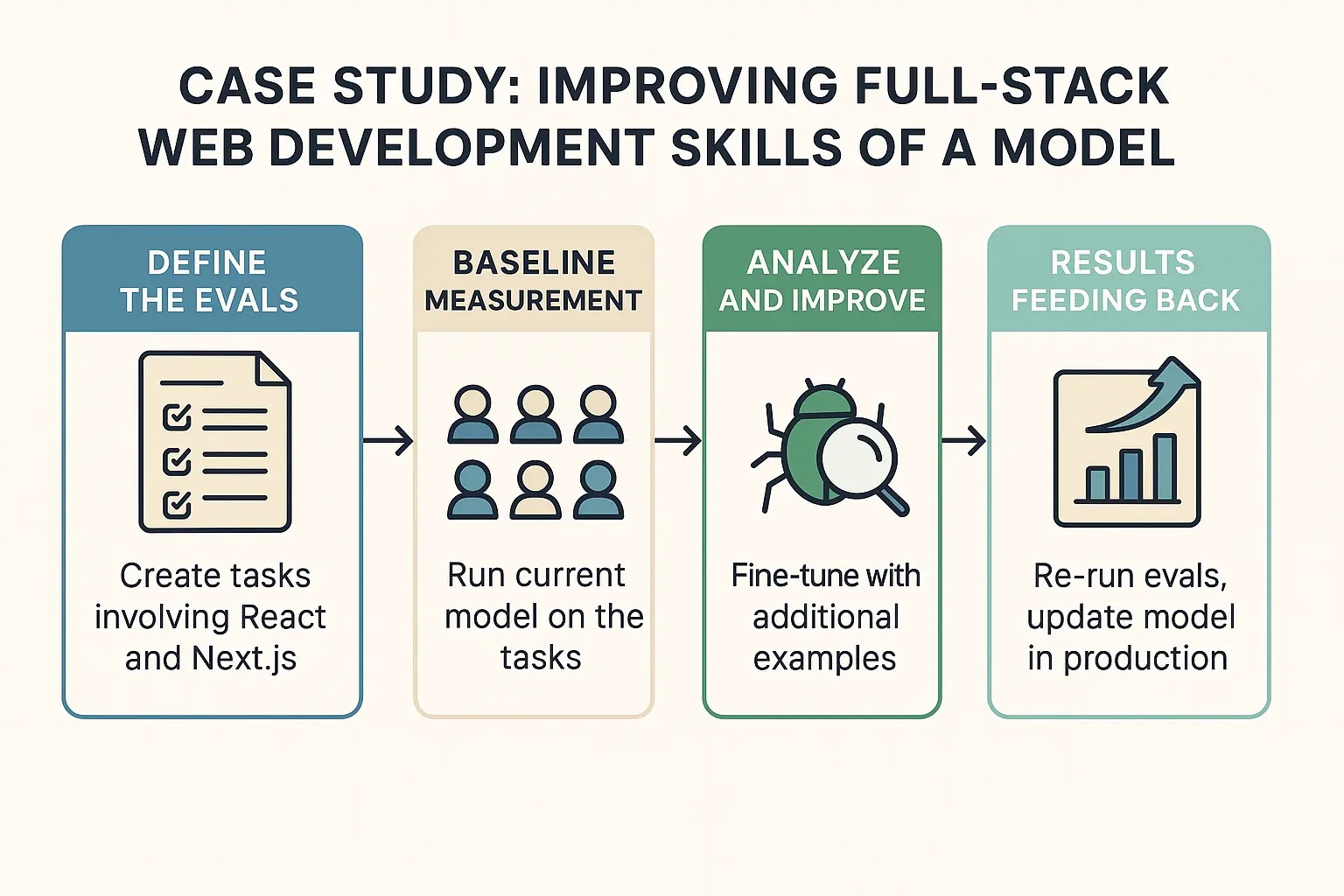
1. Define the Evals: We start by creating a set of eval tasks representative of full-stack challenges we care about. For example:
-
Task A: “Implement a Next.js API route that receives a form submission (name and email) and saves it to a database. Ensure proper error handling for missing fields and respond with JSON.” – Eval Criteria: The model’s code should compile, and when tested with various inputs (missing field, valid data, etc.), it should behave correctly (e.g., return 400 Bad Request on missing fields, save and return 200 OK with a success message on valid data). We’ll write a suite of tests (our goldens in this case are the expected responses for given inputs).
-
Task B: “Create a React component for a user profile card that displays a user’s avatar, name, and bio. It should fetch the user data from an API on mount and show a loading spinner while fetching.” – Eval Criteria: We might define that the component should use React hooks appropriately (
useState,useEffectto fetch data), show a loading state initially, then render the correct info. The golden solution is a hand-written React component that does this. We can have tests that simulate the component’s behavior (using a testing library to mount it, mock fetch responses, and verify the output UI). -
Task C: “Given a multi-file Next.js project (with pages, components, and a backend API), fix a bug where the login form is not updating the state correctly.” – Eval Criteria: This is more of a debugging task. We supply the model with a snippet of the problematic code or a description of the bug. The golden output could be a patch (diff) that fixes the bug. The eval is whether applying the model’s suggested changes resolves the issue without breaking other functionality (tested via the app’s test suite).
We create, say, 20-50 such tasks, covering a breadth of front-end and back-end scenarios (state management, routing, database calls, styling issues, etc.). This is our evaluation suite. It’s similar in spirit to how SWE-bench or LiveCodeBench include real-world tasks from GitHub issues, but tailored to our needs.
2. Baseline measurement: We run our current model on these tasks. Perhaps we do N=5 tries per task and see how many it gets right (this is where Pass@K could be used – e.g., Pass@5: does at least one out of 5 attempts solve it?). Suppose the model only correctly solves 30% of these web tasks on average, struggling particularly with Next.js-specific issues. This baseline tells us there’s lots of room for improvement.
We might notice patterns:
-
The model’s React components often forget to initialize state or clean up effects.
-
The Next.js API route solutions sometimes don’t handle async/await correctly, or don’t return proper HTTP status codes.
-
The model might be unfamiliar with certain Next.js conventions (like the
getServerSidePropsfunction or how routing works).
Each of these is a clue.
3. Analyze and improve: Now we go into hill climbing mode. For each pattern of failure, we consider how to address it:
-
For missing React state updates or effect cleanup: Perhaps the training data lacked enough modern React examples. We gather some open-source React code snippets demonstrating these patterns (or write a few examples ourselves) and fine-tune the model on them. We also adjust the prompt (system message) to remind the model about React best practices (“Always manage component state and side effects properly using hooks”).
-
For Next.js conventions: We realize the model doesn’t fully grok Next.js. We then feed it some Next.js documentation or example projects (maybe fine-tuning or in-context learning via retrieval) covering
getServerSideProps, API routes, dynamic routing, etc. -
For async handling: If the model is making mistakes with promises (e.g., forgetting
awaitor error-catching), we add more training examples focusing on proper async/await usage and perhaps enforce a rule in generation to always handle promises.
After making these changes to the model (through fine-tuning or other training techniques), we re-run the evals. Now maybe the model’s pass rate jumps to 50%. It particularly improved on tasks where it previously forgot hooks or Next.js APIs – a sign that our intervention helped. Some tasks might still be failing; for instance, maybe the model still struggles with state management in complex forms or with certain CSS-in-JS nuances. Those would be our next targets for improvement.
We continue this iterative loop. Perhaps we also incorporate some human feedback: get a senior web engineer to review some model-generated code and highlight where it’s subpar compared to the golden. That feedback can be turned into new goldens or additional training data (this is akin to reinforcement learning from human feedback (RLHF), but for code quality).
Throughout this process, our eval tasks (with their goldens) are the yardstick. They let us quantitatively answer, “Did this update make the model better at full-stack web development?” If an approach doesn’t yield better eval results, we reconsider and try something else. On the other hand, if we see steady improvement – say over a few iterations we go from 30% -> 50% -> 70% success on our tasks – we know we’re climbing in the right direction. We’d also keep an eye on broader evals (like general coding tasks) to ensure we didn’t mess up general capabilities while focusing on web dev.
It’s also worth noting that as the model improves, we might need to raise the bar with new evals. Perhaps tasks that were once challenging (and informative) become too easy for the model – it gets 90%+ on them. At that point, to continue meaningful improvement, we’d design newer, harder tasks (maybe more complex apps, or integration with other systems, etc.). This is exactly how the industry benchmarks evolved: models aced the easy stuff like basic algorithms, so benchmarks moved to include multi-file projects, API integrations, etc. We should be prepared to update our eval suite (while maintaining some core tasks to ensure no regressions on fundamentals).
4. Results feeding back: Finally, we incorporate what we’ve learned into the next version of the model that goes into production. Perhaps our fine-tuning data now includes dozens of high-quality full-stack examples and even some of the goldens from tasks the model initially failed. The released model is significantly more capable on web development queries – developers using it find that it can scaffold a Next.js app or suggest a React fix much more reliably. The cycle doesn’t end here: once users start using the model, we might gather new examples of failure from real usage, convert them into new eval tasks or goldens, and continue the hill climbing process (this becomes a continuous improvement loop, as Parea AI’s guide highlights).
Through this case study, you can see how evals guide the entire journey: from identifying weaknesses, to serving as concrete objectives during training, to validating improvements, and even to inspiring model architectural changes (e.g., maybe we decide to extend the model’s context length or equip it with a code retrieval tool after seeing it struggle with multi-file context – changes motivated by eval outcomes).
Best practices and pitfalls to avoid
Before we conclude, let’s summarize a few best practices when thinking about evals for coding models, and some pitfalls:
-
Align evals with real-world tasks: The most useful evals are those that represent what you actually want the model to be good at. If your users need full-stack help, evaluate on full-stack tasks (not just toy problems). The AI industry is increasingly shifting benchmarks from puzzle-like questions to real-world engineering challenges for this reason. When evals align with real use cases, improving eval scores translates to real user impact – you’re climbing the right hill.
-
Keep evals consistent (for comparison) but also evolve them: You need a fixed test set to compare model versions fairly. But you should also periodically introduce new tests as models get better or requirements change. Think of it like expanding your test suite in software as you add new features. Also, maintain a holdout set of eval tasks that you never train on (to truly measure generalization). Internal evals can be larger, but for formal benchmarking, having a pristine set (not seen in training) is important for trustworthiness.
-
Beware of data leakage and proxy metrics: As mentioned, if the model has seen the solution, the eval is no longer a good measure. Also, make sure your metric truly reflects success. For example, if you only measure “passes unit tests”, a model might learn to game that somehow without writing good code (e.g., by hardcoding outputs if it guesses the tests). This is usually hard in coding tasks, but in other AI tasks, proxy metrics can be gamed. Design metrics that encourage the behavior you actually want. Often a combination of metrics (functional tests + code style checks + perhaps a human review for clarity) can give a more complete picture.
-
Use evals to drive model design choices: The feedback from evals might suggest changes beyond just training data. It could indicate a need for a bigger model, or maybe a smaller one is enough. It could show benefit from a different decoding strategy (maybe allowing the model to self-refine its answer, since some models do better with multiple attempts). For instance, if evals show the model often nearly solves a task but makes a small mistake, you might implement a second-chance mechanism where the model gets to see the error (from failing a test) and try to fix it – effectively evaluating not just first-pass code, but the model’s ability to debug (some evals now explicitly measure this iterative ability).
-
Collaboration between AI and engineers: In creating and maintaining evals, involve software engineers (the domain experts). They will know what good code looks like and what tasks are important. Many top AI firms have interdisciplinary teams for this – product managers and engineers define eval success criteria that align with user needs. Also, improving coding models is as much a software engineering challenge as a machine learning one; treat the eval suite as a living testbed for your AI “feature improvements”.
In summary, evals are both measuring stick and compass. They measure how far your model has come, and they point the direction for where to go next.
Conclusion
Evals might seem like extra homework at first, but they are indispensable for systematic improvement of coding models. By carefully designing evaluation tasks (with clear goldens), using them to hill-climb through iterative enhancements, and keeping them aligned with real developer needs, we ensure that each new model version is genuinely better than the last in meaningful ways. As we saw, this approach is very analogous to how we improve software: write tests (evals), make changes (train/fine-tune), run tests, and iterate.
For those working on advanced models like Gemini or the next big coding assistant, mastering evals is key. It’s not enough to train a big model on tons of code – you have to continuously test it, understand it, and guide it. The top AI labs today heavily use eval benchmarks to drive model development, sometimes even influencing model architecture choices. The result is models that inch closer to true software engineering capability, not just coding in the small. As one evaluation study noted, there’s a shift from asking “Can it code?” to “Can it engineer?”. Evals are how we ask and answer that question.
By thinking about evals in this structured way, you as a software or ML engineer can contribute significantly to the improvement of coding models. You’ll be able to design smarter tests, diagnose model weaknesses, and ultimately deliver models that are more reliable and effective for developers. In the fast-evolving AI field, this eval-driven mindset is what turns training data and compute into real, measurable progress.
Happy hill climbing - may your models ascend to new heights!
If you enjoyed this write-up, you may also like my AI-assisted engineering series on Substack